Internet

Internet es un conjunto descentralizado de
redes de comunicación interconectadas que utilizan la familia de
protocolos TCP/IP, garantizando que las redes físicas
heterogéneas que la componen funcionen como una red lógica única, de alcance mundial. Sus orígenes se remontan a
1969, cuando se estableció la primera conexión de computadoras, conocida como
ARPANET, entre tres universidades en
California y una en
Utah,
Estados Unidos.
Uno de los servicios que más éxito ha tenido en Internet ha sido la
World Wide Web (WWW, o "la Web"), hasta tal punto que es habitual la confusión entre ambos términos. La WWW es un conjunto de protocolos que permite, de forma sencilla, la consulta remota de archivos de
hipertexto. Ésta fue un desarrollo posterior (
1990) y utiliza Internet como
medio de transmisión.
Existen, por tanto, muchos otros servicios y protocolos en Internet, aparte de la Web: el envío de
correo electrónico (
SMTP), la transmisión de archivos (
FTP y
P2P), las
conversaciones en línea (
IRC), la
mensajería instantánea y presencia, la transmisión de contenido y comunicación multimedia -
telefonía (
VoIP),
televisión (
IPTV)-, los
boletines electrónicos (
NNTP), el
acceso remoto a otros dispositivos (
SSH y
Telnet) o los
juegos en línea.
4 5 3
El
género de la palabra Internet es ambiguo, según el
Diccionario de la lengua española de la
Real Academia Española.

Esquema lógico de ARPANet.
Sus orígenes se remontan a la
década de 1960, dentro de ARPA (hoy
DARPA), como respuesta a la necesidad de esta organización de buscar mejores maneras de usar los computadores de ese entonces, pero enfrentados al problema de que los principales investigadores y laboratorios deseaban tener sus propios computadores, lo que no sólo era más costoso, sino que provocaba una duplicación de esfuerzos y recursos.
8 Así nace ARPANet (Advanced Research Projects Agency Network o Red de la Agencia para los Proyectos de Investigación Avanzada de los Estados Unidos), que nos legó el trazado de una red inicial de comunicaciones de alta velocidad a la cual fueron integrándose otras instituciones gubernamentales y redes académicas durante los años 70.
9 10 11
Investigadores, científicos, profesores y estudiantes se beneficiaron de la comunicación con otras instituciones y colegas en su rama, así como de la posibilidad de consultar la información disponible en otros centros académicos y de investigación. De igual manera, disfrutaron de la nueva habilidad para publicar y hacer disponible a otros la información generada en sus actividades.
12 13
En el mes de julio de
1961 Leonard Kleinrock publicó desde el MIT el primer documento sobre la teoría de conmutación de paquetes. Kleinrock convenció a
Lawrence Roberts de la factibilidad teórica de las comunicaciones vía paquetes en lugar de circuitos, lo cual resultó ser un gran avance en el camino hacia el trabajo informático en red. El otro paso fundamental fue hacer dialogar a los ordenadores entre sí. Para explorar este terreno, en
1965, Roberts conectó una computadora TX2 en Massachusetts con un Q-32 en California a través de una línea telefónica conmutada de baja velocidad, creando así la primera (aunque reducida) red de computadoras de área amplia jamás construida.
14 15 16
1969: La primera red interconectada nace el
21 de noviembre de
1969, cuando se crea el primer enlace entre las universidades de UCLA y Stanford por medio de la línea telefónica conmutada, y gracias a los trabajos y estudios anteriores de varios científicos y organizaciones desde
1959 (ver:
Arpanet). El
mito de que ARPANET, la primera red, se construyó simplemente para sobrevivir a ataques nucleares sigue siendo muy popular. Sin embargo, este no fue el único motivo. Si bien es cierto que ARPANET fue diseñada para sobrevivir a fallos en la red, la verdadera razón para ello era que los nodos de conmutación eran poco fiables, tal y como se atestigua en la siguiente cita:
A raíz de un estudio de RAND, se extendió el falso rumor de que ARPANET fue diseñada para resistir un ataque nuclear. Esto nunca fue cierto, solamente un estudio de RAND, no relacionado con ARPANET, consideraba la guerra nuclear en la transmisión segura de comunicaciones de voz. Sin embargo, trabajos posteriores enfatizaron la robustez y capacidad de supervivencia de grandes porciones de las redes subyacentes. (
Internet Society, A Brief History of the Internet)
1972: Se realizó la Primera demostración pública de
ARPANET, una nueva red de comunicaciones financiada por la
DARPA que funcionaba de forma distribuida sobre la
red telefónica conmutada. El éxito de ésta nueva arquitectura sirvió para que, en
1973, la
DARPA iniciara un programa de investigación sobre posibles técnicas para interconectar redes (orientadas al tráfico de paquetes) de distintas clases. Para este fin, desarrollaron nuevos
protocolos de comunicaciones que permitiesen este intercambio de información de forma "transparente" para las computadoras conectadas. De la filosofía del proyecto surgió el nombre de "Internet", que se aplicó al sistema de redes interconectadas mediante los protocolos
TCP e IP.
17
1983: El
1 de enero, ARPANET cambió el protocolo
NCP por TCP/IP. Ese mismo año, se creó el
IAB con el fin de estandarizar el protocolo TCP/IP y de proporcionar recursos de investigación a Internet. Por otra parte, se centró la función de asignación de identificadores en la
IANA que, más tarde, delegó parte de sus funciones en el
Internet registry que, a su vez, proporciona servicios a los
DNS.
18 19
1986: La
NSF comenzó el desarrollo de
NSFNET que se convirtió en la principal
Red en árbol de Internet, complementada después con las redes NSINET y ESNET, todas ellas en Estados Unidos. Paralelamente, otras redes troncales en
Europa, tanto públicas como comerciales, junto con las americanas formaban el esqueleto básico ("backbone") de Internet.
20 21
1989: Con la integración de los protocolos
OSI en la arquitectura de Internet, se inició la tendencia actual de permitir no sólo la interconexión de redes de estructuras dispares, sino también la de facilitar el uso de distintos protocolos de comunicaciones.

En 1990 el
CERN crea el código HTML y con él el primer cliente World Wide Web. En la imagen el código HTML con sintaxis coloreada.
En el
CERN de
Ginebra, un grupo de físicos encabezado por
Tim Berners-Lee creó el lenguaje
HTML, basado en el
SGML. En
1990 el mismo equipo construyó el primer cliente
Web, llamado WorldWideWeb (WWW), y el primer servidor web
A inicios de los 90, con la introducción de nuevas facilidades de interconexión y herramientas gráficas simples para el uso de la red, se inició el auge que actualmente le conocemos al Internet. Este crecimiento masivo trajo consigo el surgimiento de un nuevo perfil de usuarios, en su mayoría de personas comunes no ligadas a los sectores académicos, científicos y gubernamentales.
Esto ponía en cuestionamiento la subvención del gobierno estadounidense al sostenimiento y la administración de la red, así como la prohibición existente al uso comercial del Internet. Los hechos se sucedieron rápidamente y para 1993 ya se había levantado la prohibición al uso comercial del Internet y definido la transición hacia un modelo de administración no gubernamental que permitiese, a su vez, la integración de redes y proveedores de acceso privados.
2006: El
3 de enero, Internet alcanzó los mil cien millones de usuarios. Se prevé que en diez años, la cantidad de navegantes de la Red aumentará a 2000 millones.
El resultado de todo esto es lo que experimentamos hoy en día: la transformación de lo que fue una enorme red de comunicaciones para uso gubernamental, planificada y construida con fondos estatales, que ha evolucionado en una miríada de redes privadas interconectadas entre sí. Actualmente la red experimenta cada día la integración de nuevas redes y usuarios, extendiendo su amplitud y dominio, al tiempo que surgen nuevos mercados, tecnologías, instituciones y empresas que aprovechan este nuevo medio, cuyo potencial apenas comenzamos a descubrir.
Tecnología de Internet
Protocolo


Grafica del Usuario comun.

Paquetes de Internet de varios provedores.
Los proveedores de servicios de Internet conectar a los clientes (pensado en el "fondo" de la jerarquía de enrutamiento) a los clientes de otros ISPs. En el "top" de la jerarquía de enrutamiento son una decena de redes de nivel 1, las grandes empresas de telecomunicaciones que intercambiar tráfico directamente "a través" a todas las otras redes de nivel 1 a través de acuerdos de interconexión pendientes de pago. Nivel 2 redes de compra de tránsito a Interne
File Transfer Protocol
File Transfer Protocol
(FTP)
Familia
Familia de protocolos de Internet
Función protocolo de transferencia de archivos
Puertos 20/TCP DATA Port
21/TCP Control Port
Ubicación en la pila de protocolos
Aplicación FTP
Transporte TCP
Red IP
Estándares
FTP:
RFC 959 (
1985)
Extensiones de FTP para IPv6 y NATs:
RFC 2428 (
1998)
FTP (
siglas en
inglés de File Transfer Protocol, 'Protocolo de Transferencia de Archivos') en informática, es un
protocolo de red para la
transferencia de archivos entre sistemas conectados a una red
TCP (Transmission Control Protocol), basado en la arquitectura
cliente-servidor. Desde un equipo cliente se puede conectar a un servidor para descargar archivos desde él o para enviarle archivos, independientemente del sistema operativo utilizado en cada equipo.
El servicio FTP es ofrecido por la capa de aplicación del modelo de capas de red
TCP/IP al usuario, utilizando normalmente el
puerto de red 20 y el 21. Un problema básico de FTP es que está pensado para ofrecer la máxima velocidad en la conexión, pero no la máxima seguridad, ya que todo el intercambio de información, desde el login y password del usuario en el servidor hasta la transferencia de cualquier archivo, se realiza en
texto plano sin ningún tipo de cifrado, con lo que un posible atacante puede capturar este tráfico, acceder al servidor y/o apropiarse de los archivos transferidos.
Para solucionar este problema son de gran utilidad aplicaciones como
scp y sftp, incluidas en el paquete
SSH, que permiten transferir archivos pero
cifrando todo el tráfico.
Índice [
mostrar]
El Modelo FTP[
editar ·
editar fuente]


El siguiente modelo representa el diagrama de un servicio FTP.
En el modelo, el intérprete de protocolo (IP) de usuario inicia la conexión de control en el
puerto 21. Las órdenes FTP estándar las genera el IP de usuario y se transmiten al proceso servidor a través de la conexión de control. Las respuestas estándar se envían desde la IP del servidor la IP de usuario por la conexión de control como respuesta a las órdenes.
Estas órdenes FTP especifican parámetros para la conexión de datos (puerto de datos, modo de transferencia, tipo de representación y estructura) y la naturaleza de la operación sobre el
sistema de archivos (almacenar, recuperar, añadir, borrar, etc.). El proceso de transferencia de datos (DTP) de usuario u otro proceso en su lugar, debe esperar a que el servidor inicie la conexión al puerto de datos especificado (puerto 20 en modo activo o estándar) y transferir los datos en función de los parámetros que se hayan especificado.
Vemos también en el diagrama que la comunicación entre
cliente y
servidor es independiente del sistema de archivos utilizado en cada
computadora, de manera que no importa que sus sistemas operativos sean distintos, porque las entidades que se comunican entre sí son los PI y los DTP, que usan el mismo protocolo estandarizado: el FTP.
También hay que destacar que la conexión de datos es bidireccional, es decir, se puede usar simultáneamente para enviar y para recibir, y no tiene por qué existir todo el tiempo que dura la conexión FTP. Pero tenía en sus comienzos un problema, y era la localización de los servidores en la red. Es decir, el usuario que quería descargar algún archivo mediante FTP debía conocer en qué máquina estaba ubicado. La única herramienta de búsqueda de información que existía era Gopher, con todas sus limitaciones.
Primer buscador de información[
editar ·
editar fuente]
Gopher significa 'lanzarse sobre' la información. Es un servicio cuyo objetivo es la localización de archivos a partir de su título. Consiste en un conjunto de menús de recursos ubicados en diferentes máquinas que están intercomunicadas. Cada máquina sirve una área de información, pero su organización interna permite que todas ellas funcionen como si se tratase de una sola máquina. El usuario navega a través de estos menús hasta localizar la información buscada, y desconoce exactamente de qué máquina está descargando dicha información. Con la llegada de Internet, los potentes motores de búsqueda (Google) dejaron el servicio Gopher, y la localización de los servidores FTP dejó de ser un problema. En la actualidad, cuando el usuario se descarga un archivo a partir de un enlace de una página web no llega ni a saber que lo está haciendo desde un servidor FTP. El servicio FTP ha evolucionado a lo largo del tiempo y hoy día es muy utilizado en Internet, en redes corporativas, Intranets, etc. Soportado por cualquier sistema operativo, existe gran cantidad de software basado en el protocolo FTP.
Servidor FTP[
editar ·
editar fuente]
Un servidor FTP es un programa especial que se ejecuta en un equipo servidor normalmente conectado a Internet (aunque puede estar conectado a otros tipos de redes,
LAN,
MAN, etc.). Su función es permitir el intercambio de datos entre diferentes servidores/ordenadores.
Por lo general, los programas servidores FTP no suelen encontrarse en los ordenadores personales, por lo que un usuario normalmente utilizará el FTP para conectarse remotamente a uno y así intercambiar información con él.
Las aplicaciones más comunes de los servidores FTP suelen ser el
alojamiento web, en el que sus clientes utilizan el servicio para subir sus páginas web y sus archivos correspondientes; o como servidor de backup (copia de seguridad) de los archivos importantes que pueda tener una empresa. Para ello, existen protocolos de comunicación FTP para que los datos se transmitan cifrados, como el
SFTP (Secure File Transfer Protocol).
Cliente FTP[
editar ·
editar fuente]
Cuando un navegador no está equipado con la función FTP, o si se quiere cargar archivos en un ordenador remoto, se necesitará utilizar un programa cliente FTP. Un cliente FTP es un programa que se instala en el ordenador del usuario, y que emplea el protocolo FTP para conectarse a un servidor FTP y transferir archivos, ya sea para descargarlos o para subirlos.
Para utilizar un cliente FTP, se necesita conocer el nombre del archivo, el ordenador en que reside (servidor, en el caso de descarga de archivos), el ordenador al que se quiere transferir el archivo (en caso de querer subirlo nosotros al servidor), y la carpeta en la que se encuentra.
Algunos clientes de FTP básicos en modo consola vienen integrados en los
sistemas operativos, incluyendo
Microsoft Windows,
DOS,
GNU/Linux y
Unix. Sin embargo, hay disponibles clientes con opciones añadidas e interfaz gráfica. Aunque muchos navegadores tienen ya integrado FTP, es más confiable a la hora de conectarse con servidores FTP no anónimos utilizar un programa cliente.
Acceso anónimo[
editar ·
editar fuente]
Los servidores FTP anónimos ofrecen sus servicios libremente a todos los usuarios, permiten acceder a sus archivos sin necesidad de tener un 'USER ID' o una cuenta de usuario. Es la manera más cómoda fuera del servicio web de permitir que todo el mundo tenga acceso a cierta información sin que para ello el administrador de un sistema tenga que crear una cuenta para cada usuario.
Si un servidor posee servicio 'FTP anonymous' solamente con teclear la palabra «anonymous», cuando pregunte por tu usuario tendrás acceso a ese sistema. No se necesita ninguna contraseña preestablecida, aunque tendrás que introducir una sólo para ese momento, normalmente se suele utilizar la dirección de correo electrónico propia.
Solamente con eso se consigue acceso a los archivos del FTP, aunque con menos privilegios que un usuario normal. Normalmente solo podrás leer y copiar los archivos que sean públicos, así indicados por el administrador del servidor al que nos queramos conectar.
Normalmente, se utiliza un servidor FTP anónimo para depositar grandes archivos que no tienen utilidad si no son transferidos a la máquina del usuario, como por ejemplo programas, y se reservan los servidores de páginas web (HTTP) para almacenar información textual destinada a la lectura en línea.
Acceso de usuario[
editar ·
editar fuente]
Si se desea tener privilegios de acceso a cualquier parte del sistema de archivos del servidor FTP, de modificación de archivos existentes, y de posibilidad de subir nuestros propios archivos, generalmente se suele realizar mediante una cuenta de usuario. En el servidor se guarda la información de las distintas cuentas de usuario que pueden acceder a él, de manera que para iniciar una sesión FTP debemos introducir una
autentificación (en
inglés: login) y una
contraseña (en inglés: password) que nos identifica unívocamente.
Cliente FTP basado en Web[
editar ·
editar fuente]
Un «cliente FTP basado en Web» no es más que un cliente FTP al cual podemos acceder a través de nuestro navegador web sin necesidad de tener otra aplicación para ello. El usuario accede a un servidor web (HTTP) que lista los contenidos de un servidor FTP. El usuario se conecta mediante HTTP a un servidor web, y el servidor web se conecta mediante FTP al servidor FTP. El servidor web actúa de intermediario haciendo pasar la información desde el servidor FTP en los puertos 20 y 21 hacia el puerto 80 HTTP que ve el usuario.
Siempre hay momentos en que nos encontramos fuera de casa, no llevamos el ordenador portátil encima y necesitamos realizar alguna tarea urgente desde un ordenador de acceso público, de un amigo, del trabajo, la universidad, etc. Lo más común es que no estén instaladas las aplicaciones que necesitamos y en muchos casos hasta carecemos de los permisos necesarios para realizar su instalación. Otras veces estamos detrás de un proxy o cortafuegos que no nos permite acceder a servidores FTP externos.
Al disponer de un cliente FTP basado en Web podemos acceder al servidor FTP remoto como si estuviéramos realizando cualquier otro tipo de navegación web. A través de un cliente FTP basado en Web podrás, crear, copiar, renombrar y eliminar archivos y directorios. Cambiar permisos, editar, ver, subir y descargar archivos, así como cualquier otra función del protocolo FTP que el servidor FTP remoto permita.
Acceso de invitado[
editar ·
editar fuente]
El acceso sin restricciones al servidor que proporcionan las cuentas de usuario implica problemas de seguridad, lo que ha dado lugar a un tercer tipo de acceso FTP denominado invitado (guest), que se puede contemplar como una mezcla de los dos anteriores.
La idea de este mecanismo es la siguiente: se trata de permitir que cada usuario conecte a la máquina mediante su login y su password, pero evitando que tenga acceso a partes del sistema de archivos que no necesita para realizar su trabajo, de esta forma accederá a un entorno restringido, algo muy similar a lo que sucede en los accesos anónimos, pero con más privilegios.
Modos de conexión del cliente FTP[
editar ·
editar fuente]
FTP admite dos modos de conexión del cliente. Estos modos se denominan activo (o Estándar, o PORT, debido a que el cliente envía comandos tipo PORT al servidor por el canal de control al establecer la conexión) y pasivo (o PASV, porque en este caso envía comandos tipo PASV). Tanto en el modo Activo como en el modo Pasivo, el cliente establece una conexión con el servidor mediante el puerto 21, que establece el canal de control.
Modo activo[
editar ·
editar fuente]

Modo activo.
En modo Activo, el servidor siempre crea el canal de datos en su puerto 20, mientras que en el lado del cliente el canal de datos se asocia a un puerto aleatorio mayor que el 1024. Para ello, el cliente manda un comando PORT al servidor por el canal de control indicándole ese número de puerto, de manera que el servidor pueda abrirle una conexión de datos por donde se transferirán los archivos y los listados, en el puerto especificado.
Lo anterior tiene un grave problema de seguridad, y es que la máquina cliente debe estar dispuesta a aceptar cualquier conexión de entrada en un puerto superior al 1024, con los problemas que ello implica si tenemos el equipo conectado a una red insegura como Internet. De hecho, los
cortafuegos que se instalen en el equipo para evitar ataques seguramente rechazarán esas conexiones aleatorias. Para solucionar esto se desarrolló el modo pasivo.
Modo pasivo[
editar ·
editar fuente]
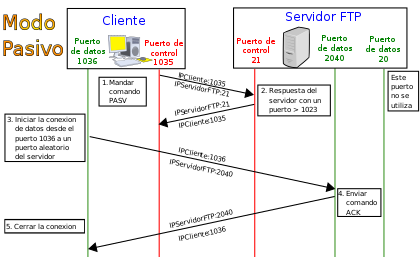
Modo pasivo.
Cuando el cliente envía un comando PASV sobre el canal de control, el servidor FTP le indica por el canal de control, el puerto (mayor a 1023 del servidor. Ejemplo:2040) al que debe conectarse el cliente. El cliente inicia una conexión desde el puerto siguiente al puerto de control (Ejemplo: 1036) hacia el puerto del servidor especificado anteriormente (Ejemplo: 2040).
1
Antes de cada nueva transferencia tanto en el modo Activo como en el Pasivo, el cliente debe enviar otra vez un comando de control (PORT o PASV, según el modo en el que haya conectado), y el servidor recibirá esa conexión de datos en un nuevo puerto aleatorio (si está en modo pasivo) o por el puerto 20 (si está en modo activo). En el protocolo FTP existen 2 tipos de transferencia en ASCII y en binarios.
Tipos de transferencia de archivos en FTP[
editar ·
editar fuente]
Es importante conocer cómo debemos transportar un archivo a lo largo de la red. Si no utilizamos las opciones adecuadas podemos destruir la información del archivo. Por eso, al ejecutar la aplicación FTP, debemos acordarnos de utilizar uno de estos comandos (o poner la correspondiente opción en un programa con interfaz gráfica):
Tipo ASCII
Adecuado para transferir archivos que sólo contengan caracteres imprimibles (archivos ASCII, no archivos resultantes de un procesador de texto), por ejemplo páginas HTML, pero no las imágenes que puedan contener.
Tipo Binario
Este tipo es usado cuando se trata de archivos comprimidos, ejecutables para PC, imágenes, archivos de audio...
Ejemplos de cómo transferir algunos tipos de archivo dependiendo de su extensión:
Extensión de archivoTipo de transferencia
txt (texto) ascii
html (página WEB) ascii
doc (documento) binario
ps (poscript) ascii
hqx (comprimido) ascii
Z (comprimido) binario
ZIP (comprimido) binario
ZOO (comprimido) binario
Sit (comprimido) binario
pit (comprimido) binario
shar (comprimido) binario
uu (comprimido) binario
ARC (comprimido) binario
tar (empaquetado) binario
para llegar a por lo menos algunas partes de la Internet mundial, aunque también pueden participar en la interconexión no remunerado (sobre todo para los socios locales de un tamaño similar). ISP puede utilizar un solo "aguas arriba" proveedor de conectividad, o utilizar multihoming para proporcionar protección contra los problemas con los enlaces individuales. Puntos de intercambio Internet crear conexiones físicas entre múltiples ISPs, a menudo alojados en edificios de propiedad de terceras partes independientes.
Los ordenadores y routers utilizan las tablas de enrutamiento para dirigir los paquetes IP entre las máquinas conectadas localmente. Las tablas pueden ser construidos de forma manual o automáticamente a través de DHCP para un equipo individual o un protocolo de enrutamiento para los routers de sí mismos. En un solo homed situaciones, una ruta por defecto por lo general apunta hacia "arriba" hacia un ISP proporciona el transporte. De más alto nivel de los ISP utilizan el Border Gateway Protocol para solucionar rutas de acceso a un determinado rango de direcciones IP a través de las complejas conexiones de la Internet global.
Las instituciones académicas, las grandes empresas, gobiernos y otras organizaciones pueden realizar el mismo papel que los ISP, con la participación en el intercambio de tráfico y tránsito de la compra en nombre de sus redes internas de las computadoras individuales. Las redes de investigación tienden a interconectarse en subredes grandes como GEANT, GLORIAD, Internet2, y de investigación nacional del Reino Unido y la red de la educación, Janet. Estos a su vez se construyen alrededor de las redes más pequeñas (véase la lista de organizaciones académicas de redes informáticas).
No todas las redes de ordenadores están conectados a Internet. Por ejemplo, algunos clasificados los sitios web de los Estados sólo son accesibles desde redes seguras independientes.
Acceso a Internet

Esquema con las tecnologías relacionadas al Internet actual.
Los métodos comunes de acceso a Internet en los hogares incluyen dial-up, banda ancha fija (a través de cable coaxial, cables de fibra óptica o cobre), Wi-Fi, televisión vía satélite y teléfonos celulares con tecnología 3G/4G. Los lugares públicos de uso del Internet incluyen bibliotecas y cafés de internet, donde los ordenadores con conexión a Internet están disponibles. También hay puntos de acceso a Internet en muchos lugares públicos, como salas de los aeropuertos y cafeterías, en algunos casos sólo para usos de corta duración. Se utilizan varios términos, como "kiosco de Internet", "terminal de acceso público", y "teléfonos públicos Web". Muchos hoteles ahora también tienen terminales de uso público, las cuales por lo general basados en honorarios. Estos terminales son muy visitada para el uso de varios clientes, como reserva de entradas, depósito bancario, pago en línea, etc Wi-Fi ofrece acceso inalámbrico a las redes informáticas, y por lo tanto, puede hacerlo a la propia Internet. Hotspots les reconocen ese derecho incluye Wi-Fi de los cafés, donde los aspirantes a ser los usuarios necesitan para llevar a sus propios dispositivos inalámbricos, tales como un ordenador portátil o
PDA. Estos servicios pueden ser gratis para todos, gratuita para los clientes solamente, o de pago. Un punto de acceso no tiene por qué estar limitado a un lugar confinado. Un campus entero o parque, o incluso una ciudad entera puede ser activado.".
Los esfuerzos de base han dado lugar a redes inalámbricas comunitarias. Los servicios comerciales de
Wi-Fi cubren grandes áreas de la ciudad están en su lugar en
Londres,
Viena,
Toronto,
San Francisco,
Filadelfia,
Chicago y
Pittsburgh. El Internet se puede acceder desde lugares tales como un banco del parque. Aparte de Wi-Fi, se han realizado experimentos con propiedad de las redes móviles inalámbricas como Ricochet, varios servicios de alta velocidad de datos a través de redes de telefonía celular, y servicios inalámbricos fijos. De gama alta los teléfonos móviles como teléfonos inteligentes en general, cuentan con acceso a Internet a través de la red telefónica. Navegadores web como Opera están disponibles en estos teléfonos avanzados, que también puede ejecutar una amplia variedad de software de Internet. Más teléfonos móviles con acceso a Internet que los PC, aunque esto no es tan ampliamente utilizado. El proveedor de acceso a Internet y la matriz del protocolo se diferencia de los métodos utilizados para obtener en línea.
Un apagón de Internet o interrupción puede ser causada por interrupciones locales de señalización. Las interrupciones de cables de comunicaciones submarinos pueden causar apagones o desaceleraciones a grandes áreas, tales como en la interrupción submarino 2008 por cable. Los países menos desarrollados son más vulnerables debido a un pequeño número de enlaces de alta capacidad. Cables de tierra también son vulnerables, como en 2011, cuando una mujer cavando en busca de chatarra de metal cortado la mayor parte de conectividad para el país de Armenia. Internet apagones que afectan a los países casi todo se puede lograr por los gobiernos como una forma de censura en Internet, como en el bloqueo de Internet en Egipto, en el que aproximadamente el 93% de las redes no tenían acceso en 2011 en un intento por detener la movilización de protestas contra el gobierno.
En un estudio norteamericano en el año 2005, el porcentaje de hombres que utilizan Internet era muy ligeramente por encima del porcentaje de las mujeres, aunque esta diferencia se invierte en los menores de 30. Los hombres se conectan más a menudo, pasan más tiempo en línea, y son más propensos a ser usuarios de
banda ancha, mientras que las mujeres tienden a hacer mayor uso de las oportunidades de comunicación (como el
correo electrónico). Los hombres eran más propensos a utilizar el Internet para pagar sus cuentas, participar en las subastas, y para la recreación, tales como la descarga de música y videos. Hombres y mujeres tenían las mismas probabilidades de utilizar Internet para hacer compras y la banca. Los estudios más recientes indican que en 2008, las mujeres superaban en número a los hombres de manera significativa en la mayoría de los sitios de redes sociales, como Facebook y Myspace, aunque las relaciones variaban con la edad. Además, las mujeres vieron más contenido de streaming, mientras que los hombres descargaron más En cuanto a los blogs, los hombres eran más propensos al blog en el primer lugar; entre los que el blog, los hombres eran más propensos a tener un blog profesional, mientras que las mujeres eran más propensas a tener un blog personal.
Nombres de dominio
Artículo principal:
Dominio de Internet.
La
Corporación de Internet para los Nombres y los Números Asignados (ICANN) es la autoridad que coordina la asignación de identificadores únicos en Internet, incluyendo nombres de dominio, direcciones de Protocolos de Internet, números del puerto del protocolo y de parámetros. Un nombre global unificado (es decir, un sistema de nombres exclusivos para sostener cada dominio) es esencial para que Internet funcione.
El ICANN tiene su sede en
California, supervisado por una Junta Directiva Internacional con comunidades técnicas, comerciales, académicas y ONG. El
gobierno de los Estados Unidos continúa teniendo un papel privilegiado en cambios aprobados en el Domain Name System. Como Internet es una red distribuida que abarca muchas redes voluntariamente interconectadas, Internet, como tal, no tiene ningún cuerpo que lo gobierne.
Usos modernos
El Internet moderno permite una mayor flexibilidad en las horas de trabajo y la ubicación. Con el Internet se puede acceder a casi cualquier lugar,a través de dispositivos móviles de Internet. Los teléfonos móviles, tarjetas de datos, consolas de juegos portátiles y routers celulares permiten a los usuarios conectarse a Internet de forma inalámbrica. Dentro de las limitaciones impuestas por las pantallas pequeñas y otras instalaciones limitadas de estos dispositivos de bolsillo, los servicios de Internet, incluyendo correo electrónico y la web, pueden estar disponibles al público en general. Los proveedores de internet puede restringir los servicios que ofrece y las cargas de datos móviles puede ser significativamente mayor que otros métodos de acceso.
Se puede encontrar material didáctico a todos los niveles, desde preescolar hasta post-doctoral está disponible en sitios web. Los ejemplos van desde CBeebies, a través de la escuela y secundaria guías de revisión, universidades virtuales, al acceso a la gama alta de literatura académica a través de la talla de Google Académico. Para la educación a distancia, ayuda con las tareas y otras asignaciones, el auto-aprendizaje guiado, entreteniendo el tiempo libre, o simplemente buscar más información sobre un hecho interesante, nunca ha sido más fácil para la gente a acceder a la información educativa en cualquier nivel, desde cualquier lugar. El Internet en general es un importante facilitador de la educación tanto formal como informal.
El bajo costo y el intercambio casi instantáneo de las ideas, conocimientos y habilidades han hecho el trabajo colaborativo dramáticamente más fácil, con la ayuda del software de colaboración. De chat, ya sea en forma de una sala de chat IRC o del canal, a través de un sistema de mensajería instantánea, o un sitio web de redes sociales, permite a los colegas a mantenerse en contacto de una manera muy conveniente cuando se trabaja en sus computadoras durante el día. Los mensajes pueden ser intercambiados de forma más rápida y cómodamente a través del correo electrónico. Estos sistemas pueden permitir que los archivos que se intercambian, dibujos e imágenes para ser compartidas, o el contacto de voz y vídeo entre los miembros del equipo.
Sistemas de gestión de contenido permiten la colaboración a los equipos trabajar en conjuntos de documentos compartidos al mismo tiempo, sin destruir accidentalmente el trabajo del otro. Los equipos de negocio y el proyecto pueden compartir calendarios, así como documentos y otra información. Esta colaboración se produce en una amplia variedad de áreas, incluyendo la investigación científica, desarrollo de software, planificación de la conferencia, el activismo político y la escritura creativa. La colaboración social y político es cada vez más generalizada, como acceso a Internet y difusión conocimientos de informática.
La Internet permite a los usuarios de computadoras acceder remotamente a otros equipos y almacenes de información fácilmente, donde quiera que estén. Pueden hacer esto con o sin la seguridad informática, es decir, la autenticación y de cifrado, dependiendo de los requerimientos. Esto es alentador, nuevas formas de trabajo, la colaboración y la información en muchas industrias. Un contador sentado en su casa puede auditar los libros de una empresa con sede en otro país. Estas cuentas podrían haber sido creado por trabajo desde casa tenedores de libros, en otros lugares remotos, con base en la información enviada por correo electrónico a las oficinas de todo el mundo. Algunas de estas cosas eran posibles antes del uso generalizado de Internet, pero el costo de líneas privadas arrendadas se han hecho muchos de ellos no factibles en la práctica. Un empleado de oficina lejos de su escritorio, tal vez al otro lado del mundo en un viaje de negocios o de placer, pueden acceder a sus correos electrónicos, acceder a sus datos usando la computación en nube, o abrir una sesión de escritorio remoto a su PC de la oficina usando un seguro virtual Private Network (VPN) en Internet. Esto puede dar al trabajador el acceso completo a todos sus archivos normales y datos, incluyendo aplicaciones de correo electrónico y otros, mientras que fuera de la oficina. Este concepto ha sido remitido a los administradores del sistema como la pesadilla privada virtual, [36], ya que amplía el perímetro de seguridad de una red corporativa en lugares remotos y las casas de sus empleados.
Impacto social

Sitios de Internet por países.
Internet tiene un impacto profundo en el
mundo laboral, el
ocio y el
conocimiento a nivel mundial. Gracias a la web, millones de personas tienen acceso fácil e inmediato a una cantidad extensa y diversa de
información en línea. Este nuevo
medio de comunicación logró romper las barreras físicas entre regiones remotas, sin embargo el idioma continua siendo una dificultad importante. Si bien en un principio nació como un medio de comunicación unilateral destinado a las
masas, su evolución en la llamada
Web 2.0 permitió la participación de los ahora emisores-receptores, creandose así variadas y grandes plazas públicas como puntos de encuentro en el espacio digital.
Comparado a las
enciclopedias y a las
bibliotecas tradicionales, la web ha permitido una descentralización repentina y extrema de la información y de los datos. Algunas compañías e individuos han adoptado el uso de los
weblogs, que se utilizan en gran parte como diarios actualizables, ya en decadencia tras la llegada de las
plataformas sociales. La automatización de las bases de datos y la posibilidad de convertir cualquier computador en una terminal para acceder a ellas, ha traído como consecuencia la
digitalización de diversos trámites, transacciones bancarias o consultas de cualquier tipo, ahorrando costos administrativos y tiempo del usuario. Algunas organizaciones comerciales animan a su personal para incorporar sus áreas de especialización en sus sitios, con la esperanza de que impresionen a los visitantes con conocimiento experto e información libre.
30
Esto también ha permitido la creación de proyectos de colaboración mundial en la creación de software
libre y de
código abierto (
FOSS), por ejemplo: la
Free Software Foundation con sus herramientas
GNU y
licencia de contenido libre, el núcleo de sistema operativo
Linux, la
Fundación Mozilla con su navegador web
Firefox y su lector de correos
Thunderbird, la suite ofimática
Apache OpenOffice y la propia
Fundación Wikimedia.
31 32
Internet se extendió globalmente, no obstante, de manera desigual. Floreció en gran parte de los hogares y empresas de países ricos, mientras que países y sectores desfavorecidos cuentan con baja penetración y velocidad promedio de Internet. La inequidad del acceso a esta nueva tecnología se le conoce como
brecha digital, lo que repercute menores oportunidades de conocimiento, comunicación y cultura. No obstante a lo largo de las décadas se observa un crecimiento sostenido tanto en la penetración y velocidad de Internet, implementándose gradualmente en todas las naciones, como en su volumen de datos almacenados y el ancho de banda total usado en el intercambio de información por día.
Ocio
Muchos utilizan Internet para descargar música, películas y otros trabajos. Hay fuentes que cobran por su uso y otras gratuitas, usando los servidores centralizados y distribuidos, las tecnologías de
P2P. Otros utilizan la red para tener acceso a las noticias y el estado del tiempo.
La mensajería instantánea o
chat y el correo electrónico son algunos de los servicios de uso más extendido. En muchas ocasiones los proveedores de dichos servicios brindan a sus afiliados servicios adicionales como la creación de espacios y perfiles públicos en donde los internautas tienen la posibilidad de colocar en la red fotografías y comentarios personales. Se especula actualmente si tales sistemas de comunicación fomentan o restringen el contacto de persona a persona entre los seres humanos.[
cita requerida]
En tiempos más recientes han cobrado auge portales como
YouTube o
Facebook, en donde los usuarios pueden tener acceso a una gran variedad de videos sobre prácticamente cualquier tema.
La
pornografía representa buena parte del tráfico en Internet, siendo a menudo un aspecto controvertido de la red por las implicaciones morales que le acompañan. Proporciona a menudo una fuente significativa del rédito de publicidad para otros sitios. Muchos gobiernos han procurado sin éxito poner restricciones en el uso de ambas industrias en Internet.
El sistema
multijugador constituye también buena parte del ocio en Internet.
Internet y su evolución
Inicialmente Internet tenía un objetivo claro. Se navegaba en Internet para algo muy concreto: búsquedas de información, generalmente. Ahora quizás también, pero sin duda alguna hoy es más probable perderse en la red, debido al inmenso abanico de posibilidades que brinda. Hoy en día, la sensación que produce Internet es un ruido, una serie de interferencias, una explosión de ideas distintas, de personas diferentes, de pensamientos distintos de tantas posibilidades que, en ocasiones, puede resultar excesivo. El crecimiento o más bien la incorporación de tantas personas a la red hace que las calles de lo que en principio era una pequeña ciudad llamada Internet se conviertan en todo un planeta extremadamente conectado entre sí entre todos sus miembros. El hecho de que Internet haya aumentado tanto implica una mayor cantidad de relaciones virtuales entre personas. Es posible concluir que cuando una persona tenga una necesidad de conocimiento no escrito en libros, puede recurrir a una fuente más acorde a su necesidad. Como ahora esta fuente es posible en Internet. Como toda gran revolución, Internet augura una nueva era de diferentes métodos de resolución de problemas creados a partir de soluciones anteriores. Algunos sienten que Internet produce la sensación que todos han sentido sin duda alguna vez; produce la esperanza que es necesaria cuando se quiere conseguir algo. Es un despertar de intenciones que jamás antes la tecnología había logrado en la población mundial. Para algunos usuarios Internet genera una sensación de cercanía, empatía, comprensión y, a la vez, de confusión, discusión, lucha y conflictos que los mismos usuarios consideran la vida misma.
La evolución del internet radica en la migración de la versión y uso del IPv4 a IPv6. IP es un protocolo que no está orientado a la conexión y no es completamente seguro en la transmisión de los datos, lo anterior permite que las conexiones inalámbricas tengan siempre movilidad. Por otro lado, para mejorar la confiabilidad se usa el protocolo TCP. El protocolo IP, es la forma en la que se enrutan los paquetes entre las redes. Cada nodo en cada una de las redes tiene una dirección IP diferente. Para garantizar un enrutamiento correcto, IP agrega su propio encabezado a los paquetes. Este proceso se apoya en tablas de enrutamiento que son actualizadas permanentemente. En caso de que el paquete de datos sea demasiado grande, el protocolo IP lo fragmenta para poderlo transportar. La versión que se está ocupando de este protocolo es la 4, donde se tiene conectividad, pero también ciertas restricciones de espacio. Es por eso que la grandes empresas provedoras del servicio de internet migraran a la versión IPv6.
La nueva versión del protocolo IP Internet Protocol recibe el nombre de IPv6, aunque es también conocido comúnmente como IPng Internet Protocol Next Generation. IPv6 ha sido diseñado como un paso evolutivo desde IPv4, por lo que no representa un cambio radical respecto IPv4. Las características de IPv4 que trabajan correctamente se han mantenido en el nuevo protocolo, mientras que se han suprimido aquéllas que no funcionaban bien. De todos modos, los cambios que se introducen en esta nueva versión son muchos y de gran importancia debido a las bondades que ofrecen. A principios de 2010, quedaban menos del 10% de IPs sin asignar. En la semana del 3 de febrero del 2011, la IANA (Agencia Internacional de Asignación de Números de Internet, por sus siglas en inglés) entregó el último bloque de direcciones disponibles (33 millones) a la organización encargada de asignar IPs en Asia, un mercado que está en auge y no tardará en consumirlas todas. IPv4 posibilita 4,294,967,296 (232) direcciones de red diferentes, un número inadecuado para dar una dirección a cada persona del planeta, y mucho menos a cada vehículo, teléfono, PDA, etcétera. En cambio, IPv6 admite 340.282.366.920.938.463.463.374.607.431.768.211.456 (2128 o 340 sextillones de direcciones) —cerca de 6,7 × 1017 (670 milbillones) de direcciones por cada milímetro cuadrado de la superficie de La Tierra. Otra vía para la popularización del protocolo es la adopción de este por parte de instituciones. El Gobierno de los Estados Unidos ordenó el despliegue de IPv6 por todas sus agencias federales en el año 2008.
Fuente de información
En 2009, un estudio realizado en
Estados Unidos indicó que un 56% de los 3.030 adultos estadounidenses entrevistados en una encuesta online manifestó que si tuviera que escoger una sola fuente de información, elegiría Internet, mientras que un 21% preferiría la televisión y tanto los periódicos como la radio sería la opción de un 10% de los encuestados. Dicho estudio posiciona a los medios digitales en una posición privilegiada en cuanto a la búsqueda de información y refleja un aumento de la credibilidad en dichos medios.
33 34
Buscadores
Un buscador se define como el sistema informático que indexa archivos almacenados en servidores web cuando se solicita información sobre algún tema. Por medio de palabras clave, se realiza la exploración y el buscador muestra una lista de direcciones con los temas relacionados. Existen diferentes formas de clasificar los buscadores según el proceso de sondeo que realizan. La clasificación más frecuente los divide en: índices o directorios temáticos,
motores de búsqueda y metabuscadores.
Índices o directorios temáticos
Los índices o buscadores temáticos son sistemas creados con la finalidad de diseñar un catálogo por temas, definiendo la clasificación por lo que se puede considerar que los contenidos ofrecidos en estas páginas tienes ya cierto orden y calidad.
La función de este tipo de sistemas es presentar algunos de los datos de las páginas más importantes, desde el punto de vista del tema y no de lo que se contiene. Los resultados de la búsqueda de esta de estos índices pueden ser muy limitados ya que los directorios temáticos, las bases de datos de direcciones son muy pequeñas, además de que puede ser posible que el contenido de las páginas no esté completamente al día.
Motores de búsqueda
Artículo principal:
Motor de búsqueda.
Este tipo de buscadores son los de uso más común, basados en aplicaciones llamadas spiders ("arañas") o robots, que buscan la información con base en las palabras escritas, haciendo una recopilación sobre el contenido de las páginas y mostrando como resultado aquéllas que contengan la palabra o frase en alguna parte del texto.
Metabuscadores
Los metabuscadores son sistemas que localizan información en los motores de búsqueda más utilizados, realizan un análisis y seleccionan sus propios resultados. No tienen una base de datos, por lo que no almacenan páginas web y realizan una búsqueda automática en las bases de datos de otros buscadores, de los cuales toma un determinado rango de registros con los resultados más relevantes y así poder tener la información necesaria.
Trabajo
Con la aparición de Internet y de las
conexiones de alta velocidad disponibles al público, Internet ha alterado de manera significativa la manera de trabajar de algunas personas al poder hacerlo desde sus respectivos hogares. Internet ha permitido a estas personas mayor flexibilidad en términos de horarios y de localización, contrariamente a la jornada laboral tradicional, que suele ocupar la mañana y parte de la tarde, en la cual los empleados se desplazan al lugar de trabajo.
Un experto contable asentado en un país puede revisar los libros de una compañía en otro país, en un servidor situado en un tercer país que sea mantenido remotamente por los especialistas en un cuarto.
Internet y sobre todo los
blogs han dado a los trabajadores un foro en el cual expresar sus opiniones sobre sus empleos, jefes y compañeros, creando una cantidad masiva de información y de datos sobre el trabajo que está siendo recogido actualmente por el colegio de abogados de
Harvard.
Internet ha impulsado el fenómeno de la
Globalización y junto con la llamada
desmaterialización de la economía ha dado lugar al nacimiento de una
Nueva Economía caracterizada por la utilización de la red en todos los procesos de incremento de valor de la empresa
Publicidad
Artículo principal:
Publicidad en Internet.
Internet se ha convertido en el medio más fácilmente medible y de más alto crecimiento en la historia. Actualmente existen muchas empresas que obtienen dinero de la publicidad en Internet. Además, existen mucha ventajas que la publicidad interactiva ofrece tanto para el usuario como para los anunciantes.
Censura
Es extremadamente difícil, si no imposible, establecer control centralizado y global de Internet. Algunos gobiernos, de naciones tales como
Irán,
Arabia Saudita,
Corea del Norte, la
República Popular de China y
Estados Unidos restringen el que personas de sus países puedan ver ciertos contenidos de Internet, políticos y religiosos, considerados contrarios a sus criterios. La censura se hace, a veces, mediante filtros controlados por el gobierno, apoyados en leyes o motivos culturales, castigando la propagación de estos contenidos. Sin embargo, muchos usuarios de Internet pueden burlar estos filtros, pues la mayoría del contenido de Internet está disponible en todo el mundo, sin importar donde se esté, siempre y cuando se tengan la habilidad y los medios técnicos necesarios.
35
Otra posibilidad, como en el
caso de China, es que este tipo de medidas se combine con la
autocensura de las propias empresas proveedoras de servicios de Internet, serían las empresas equivalentes a Telefónicas (proveedores de servicios de Internet), para así ajustarse a las demandas del gobierno del país receptor.
36
Sin embargo algunos buscadores como
Google, han tomado la decisión de amenazar al gobierno de China con la retirada de sus servicios en dicho país si no se abole la censura en Internet. Aunque posteriormente haya negado que tomará dichas medidas
37
Para saltarse cualquier tipo de censura o
coerción en el uso de internet, se han desarrollado múltiples tecnologías y herrramientas. Entre ellas cabe resaltar por un lado las técnicas y herramientas
criptológicas y por otro lado las tecnologías encuadradas en la llamada
Darknet. La
Darknetes una colección de redes y tecnologías que persiguen la consecución de un anonimato total de los comunicantes, creando de esta forma una zona de total libertad. Aunque actualmente no se suele considerar que consigan un anonimato total, sin embargo, sí consiguen una mejora sustancial en la privacidad de los usuarios. Este tipo de redes se han usado intensamente, por ejemplo, en los sucesos de la
Primavera Árabe y en todo el entramado de
wikileaks para la publicación de información confidencial. Las tecnologías de la
Darknet están en fase de perfeccionamiento y mejora de sus prestaciones.
38
Internet en obras de ficción
Artículo principal:
Internet en la ciencia ficción.
Internet aparece muchas veces en obras de
ficción. Puede ser un elemento más de la trama, algo que se usa de forma habitual tal y como se hace en la vida real.
También hay obras donde Internet se presenta como un medio maligno que permite a
hackers sembrar el caos, alterar registros, como por ejemplo, las
películas La Red,
Live Free or Die Hard, etc. Hay otras obras donde aparece como una gran oportunidad para la
libertad de expresión (por ejemplo, la película
FAQ: Frequently Asked Questions).
Tamaño
Un estudio del año 2005 usando distintos motores de búsqueda (
Google, MSN,
Yahoo! y
Ask Jeeves) estimaba que existían 11.500 millones de páginas Web. Otro estudio del año 2008 estimaba que la cantidad había ascendido a 63.000 millones de páginas web.
Sin embargo es difícil establecer el tamaño exacto de Internet, ya que este crece continuamente y no existe una manera fiable de acceder a todo su contenido y, por consiguiente, de determinar su tamaño. Para estimar esta cantidad se usan las webs indexadas por los distintos motores de búsqueda, pero este método no abarca todas las páginas online. Utilizando este criterio Internet se puede dividir en:
Internet superficial: Incluye los servicios indexados por los motores de búsqueda.
Internet profunda: Incluye el resto de servicios no indexados como páginas en Flash, páginas protegidas por contraseña, inaccesibles para las arañas, etc. Se estima que el tamaño de la Internet profunda es varios órdenes de magnitud mayor que el de Internet superficial.
Usuarios

Gráfica que representa el número de usuarios de Internet.
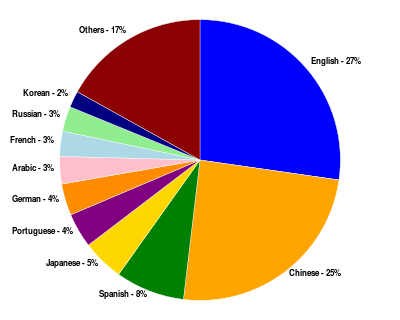
Idiomas usados en Internet.
En general el uso de Internet ha experimentado un tremendo crecimiento. De 2000 a 2009, el número de usuarios de Internet a nivel mundial aumentó 394 millones a 1858 millones. En 2010, el 22 por ciento de la población mundial tenía acceso a las computadoras con mil millones de búsquedas en Google cada día, 300 millones de usuarios de Internet leen blogs, y 2 mil millones de vídeos vistos al día en YouTube.
El idioma predominante de la comunicación en Internet ha sido inglés. Este puede ser el resultado del origen de la Internet, así como el papel de la lengua como lengua franca. Los primeros sistemas informáticos se limitaban a los personajes en el Código Estándar Americano para Intercambio de Información (ASCII), un subconjunto del alfabeto latino.
Después de inglés (27%), los idiomas más solicitados en la World Wide Web son el chino (23%), español (8%), japonés (5%), portugués y alemán (4% cada uno), árabe, francés y ruso (3% cada uno) y coreano (2%). Por regiones, el 42% de los usuarios de Internet en el mundo están en Asia, 24% en Europa, el 14% en América del Norte, el 10% en Iberoamérica y el Caribe, adoptado en conjunto, un 6% en África, 3% en el Oriente Medio y un 1% en Oceanía. Las tecnologías de la Internet se han desarrollado lo suficiente en los últimos años, especialmente en el uso de Unicode, que con buenas instalaciones están disponibles para el desarrollo y la comunicación en los idiomas más utilizados del mundo. Sin embargo, algunos problemas, tales como la visualización incorrecta de caracteres de algunos idiomas, aún permanecen.
En un estudio norteamericano en el año 2005, el porcentaje de varones que utilizan internet estaba muy ligeramente por encima del porcentaje de las mujeres, aunque esta diferencia estaba invertida en los menores de 30 años. Los hombres se conectaron más a menudo, pasan más tiempo en línea, y eran más propensos a ser usuarios de banda ancha, mientras que las mujeres tienden a hacer mayor uso de las oportunidades de comunicación, como el correo electrónico. Los hombres eran más propensos a utilizar el internet para pagar sus cuentas, participar en las subastas, y para la recreación, tales como la descarga de música y videos. Ambos sexos tenían las mismas probabilidades de utilizar internet para hacer compras y la banca. Los estudios más recientes indican que en 2008, las mujeres superaban en número a los hombres de manera significativa en la mayoría de los sitios de redes sociales, como Facebook y Myspace, aunque las relaciones variaban con la edad. Además, las mujeres vieron más contenido de streaming, mientras que los hombres descargaron más. En cuanto a los blogs, los varones eran más propensos a tener uno profesional, mientras que las mujeres eran más propensas a tener un blog personal.
Dominio de Internet
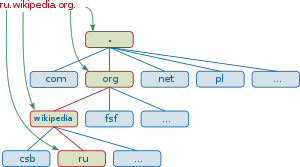
Ilustración de los diferentes niveles de un dominio de internet.
Un dominio de Internet es una red de identificación asociada a un grupo de dispositivos o equipos conectados a la red
Internet.
El propósito principal de los nombres de dominio en Internet y del
sistema de nombres de dominio (DNS), es traducir las
direcciones IP de cada nodo activo en la red, a términos memorizables y fáciles de encontrar. Esta abstracción hace posible que cualquier servicio (de red) pueda moverse de un lugar geográfico a otro en la red Internet, aún cuando el cambio implique que tendrá una dirección IP diferente.
1
Sin la ayuda del sistema de nombres de dominio, los usuarios de Internet tendrían que acceder a cada servicio web utilizando la dirección IP del nodo (por ejemplo, sería necesario utilizar http://192.0.32.10 en vez de http://example.com). Además, reduciría el número de webs posibles, ya que actualmente es habitual que una misma dirección IP sea compartida por varios dominios.
URL frente a nombre de dominio
El siguiente ejemplo ilustra la diferencia entre una URL (Uniform Resource Locator/"Recurso de Localización Uniforme") y un nombre de dominio:
URL: http://www.ejemplo.net/index.html
Nombre de dominio de nivel superior: net
nombre de dominio: ejemplo.net
nombre de host: www.ejemplo.net
Organización del espacio de nombres

El sistema jerárquico de nombres de dominio, organizado en zonas, cada una atendida por servidores de nombre de dominio.
Dominios de nivel superior
Cuando se creó el Sistema de Nombres de Dominio en los años 80, el espacio de nombres se dividió en dos . El primero incluye los dominios, basados en los dos caracteres de identificación de cada territorio de acuerdo a las abreviaciones del ISO-3166. (Ej. *.do, *.mx) y se denomina ccTLD (Dominio de nivel superior de código de país o Country Code Top level Domain), los segundos, incluyen un grupo de siete dominios de primer nivel genéricos, (gTLD), que representan una serie de nombres y multi-organizaciones: GOB, EDU, COM, MIL, ORG, NET e INT.
Los dominios basados en ccTLD son administrados por organizaciones sin fines de lucro en cada país, delegada por la IANA y o ICANN para la administración de los dominios territoriales
El crecimiento de Internet ha implicado la creación de nuevos dominios gTLD. A mayo de 2012, existen 22 gTLD y 293 ccTLD.
Alojamiento web

El alojamiento web (en
inglés web hosting) es el servicio que provee a los
usuarios de
Internet un sistema para poder almacenar información, imágenes, vídeo, o cualquier contenido accesible vía web. Es una analogía de "hospedaje o alojamiento en hoteles o habitaciones" donde uno ocupa un lugar específico, en este caso la analogía alojamiento web o alojamiento de páginas web, se refiere al lugar que ocupa una página web,
sitio web, sistema,
correo electrónico, archivos etc. en
interneto más específicamente en un servidor que por lo general hospeda varias aplicaciones o páginas web.
Las compañías que proporcionan espacio de un
servidor a sus clientes se suelen denominar con el término en inglés web host.
El hospedaje web aunque no es necesariamente un servicio, se ha convertido en un lucrativo negocio para las compañías de internet alrededor del mundo.
Se puede definir como "un lugar para tu página web o correos electrónicos", aunque esta definición simplifica de manera conceptual el hecho de que el alojamiento web es en realidad espacio en Internet para prácticamente cualquier tipo de información, sea archivos, sistemas, correos electrónicos, videos etc.
Tipos de alojamiento web en Internet
Según las necesidades específicas de un usuario, existen diferentes tipos de alojamiento web
1 entre los cuales el usuario ha de elegir la opción acorde a sus necesidades. Entre los principales tipos de alojamiento web se encuentran:
Alojamiento gratuito
El alojamiento gratuito es extremadamente limitado cuando se lo compara con el alojamiento de pago. Estos servicios generalmente agregan publicidad en los sitios y tienen un espacio y tráfico limitado.
Alojamiento compartido
En este tipo de servicio se alojan clientes de varios
sitios en un mismo servidor, gracias a la configuración del
programa servidor web. Resulta una alternativa muy buena para pequeños y medianos clientes, es un servicio económico debido a la reducción de costos ya que al compartir un servidor con cientos miles o millones de personas o usuarios el costo se reduce drásticamente para cada uno, y tiene buen rendimiento.
Entre las desventajas de este tipo de hospedaje web hay que mencionar sobre todo el hecho de que compartir los recursos de
hardware de un servidor entre cientos o miles de usuarios disminuye notablemente el desempeño del mismo. Es muy usual también que las fallas ocasionadas por un usuario repercutan en los demás por lo que el administrador del servidor debe tener suma cautela al asignar permisos de ejecución y escritura a los usuarios. En resumen las desventajas son: disminución de los recursos del servidor, de velocidad, de desempeño, de seguridad y de estabilidad.
Alojamiento de imágenes
Este tipo de hospedaje se ofrece para guardar
imágenes en internet, la mayoría de estos servicios son gratuitos y las páginas se valen de la publicidad colocadas en su página al subir la imagen.
Alojamiento revendedor (reseller)
Este servicio de alojamiento está diseñado para grandes usuarios o personas que venden el servicio de hospedaje a otras personas. Estos paquetes cuentan con gran cantidad de espacio y de dominios disponibles para cada cuenta. Así mismo estos espacios tienen un límite de capacidad de clientes y dominios alojados y por ende exige buscar un servidor dedicado.
Servidores virtuales (VPS, Virtual Private Server)
Artículo principal:
Servidor virtual.
La empresa ofrece el control de una
computadora aparentemente no compartida, que se realiza mediante una
máquina virtual. Así se pueden administrar varios dominios de forma fácil y económica, además de elegir los programas que se ejecutan en el servidor. Por ello, es el tipo de producto recomendado para empresas de diseño y programación web.
Servidores dedicados
Un servidor dedicado es una
computadora comprada o arrendada que se utiliza para prestar servicios dedicados, generalmente relacionados con el alojamiento web y otros servicios en red. A diferencia de lo que ocurre con el alojamiento compartido, en donde los recursos de la máquina son compartidos entre un número indeterminado de clientes, en el caso de los servidores dedicados, generalmente es un sólo cliente el que dispone de todos los recursos de la máquina para los fines por los cuales haya contratado el servicio.
Los servidores dedicados pueden ser utilizados tanto para prestar servicios de alojamiento compartido como para prestar servicios de alojamiento dedicado, y pueden ser administrados por el cliente o por la empresa que los provee. El cuidado físico de la máquina y de la conectividad a Internet está generalmente a cargo de la empresa que provee el servidor. Un servidor dedicado generalmente se encuentra localizado en un
centro de datos.
Un servidor dedicado puede ser entendido como la contraparte del alojamiento web compartido, pero eso no significa que un servidor dedicado no pueda ser destinado a entregar este tipo de servicio. Este es el caso cuando, por ejemplo, una empresa dedicada al negocio del alojamiento web compra o arrienda un servidor dedicado con el objetivo de ofrecer servicios de alojamiento web a sus clientes.
Por otro lado, un servidor dedicado puede ser utilizado como una forma avanzada de alojamiento web cuando un cliente o empresa tiene requerimientos especiales de rendimiento, configuración o seguridad. En estos casos es común que una empresa arriende un servidor dedicado para autoabastecerse de los servicios que necesita disponiendo de todos los recursos de la máquina.
La principal desventaja de un servidor dedicado es el costo del servicio, el cual es muy superior al del alojamiento compartido. Esto debido principalmente al costo mensual de la máquina y la necesidad de contratar los servicios para la administración y configuración del servidor.
Hosting Administrado y No Administrado
Algunas compañías ofrecen a sus clientes mejores precios si contratan un plan de alojamiento "No Administrado" esto quiere decir que ellos se limitarán a ofrecer la conectividad, recursos, panel de control y todas las herramientas necesarias para administrar el plan contratado pero no le brindarán asistencia para los fallos, desconfiguraciones, o errores causados por la aplicación web que se este ejecutando (CMS, archivos de PHP, HTML) los cuales deben ser administrados enteramente por el webmaster del sitio web.
En el "Alojamiento Administrado" normalmente conlleva un precio más alto pero el soporte técnico incluye una cierta cantidad de incidencias / horas en el lapso de un mes o un año según el plan contratado y usted puede solicitar ayudar para remediar problemas en sus scripts, errores de ejecución u otros similares.
Colocación (housing)
Este servicio consiste básicamente en vender o alquilar un espacio físico de un
centro de datos para que el cliente coloque ahí su propia computadora. La empresa le da la corriente y la conexión a Internet, pero el servidor lo elige completamente el usuario (hasta el hardware).
Alojamiento web en la nube (cloud hosting)
Artículo principal:
Computación en la nube.
El alojamiento web en la "nube" (cloud hosting) está basado en las tecnologías más innovadoras que permiten a un gran número de máquinas actuar como un sistema conectadas a un grupo de medios de almacenamiento, tiene ventajas considerables sobre las soluciones de web hostingtradicionales tal como el uso de recursos. La seguridad de un sitio web alojado en la "nube" (cloud) está garantizada por numerosos servidores en lugar de sólo uno. La tecnología de
computación en la nube también elimina cualquier limitación física para el crecimiento en tiempo real y hace que la solución sea extremadamente flexible.
Formas de obtener
Por lo general, se distingue entre servicios de pago y servicios gratuitos.
Servicios de pago
Este tipo de obtención, por lo general viene dado por el contrato de un
proveedor de internet, el cual junto con dar conexión, entre la posibilidad de almacenamiento mediante
disco virtual o
espacio web o combinación de ambos.
Otro medio de obtención es contratando algún servicio de una empresa no dependiente de la conexión a internet, las cuales ofrecen según las capacidades de sus servidores o de su espacio. Casi siempre a la par, entregan servicios añadidos, como la ejecución de tareas automáticas o cuentas de
correo electrónico gratuitas.
Normalmente las transacciones son electrónicas, por tarjeta de crédito o por sistemas de pagos como
PayPal.
Servicios gratuitos
Este tipo de servicio viene dado por la base de ser gratuito, y sin costo alguno al suscriptor. Sin embargo, quienes usan este servicio, por lo general son páginas de bajos recursos de mantenimiento o aquellas que los dueños no poseen suficiente dinero para ser mantenida.
Como medio de financiamiento, el servidor coloca avisos de publicidad de
Adsense u otras empresas, haciendo que la página se llene de publicidad en algún punto.
Otra limitación de estas ofertas es que tiene un espacio limitado y no se puede usar como almacén de datos, ni pueden alojar páginas subversivas o de contenido adulto o no permitido.
De todas maneras, existe una amplia oferta de alojamientos gratuitos con características muy diferentes y que pueden satisfacer las necesidades de programadores que desean un lugar donde hacer pruebas o que mantienen un sitio con un número no muy elevado de visitas.
Servidores y servicios
Un alojamiento web se puede diferenciar de otro por el tipo de sistema operativo, uso de bases de datos y motor de generación de sitios web exista en él. La combinación más conocida y extendida es la del tipo
LAMP (
Linux,
Apache,
MySQL y
PHP), aunque se está comenzando a usar una combinación con
Java.
Los servicios más comunes que se pueden incluidos en un hosting son los siguientes:
Alojamiento de ficheros y acceso vía web a los ficheros para subidas, descargas, edición, borrado, etc.
Acceso a ficheros vía
FTP.
Creación de bases de datos, típicamente
MySQL en el caso de alojamientos basados en Linux y administración vía web de las basea de datos con herramientas web como
phpMyAdmin.
Cuentas de correo electrónico con dominio propio, gestión de listas de correo, acceso vía clientes de sobremesa (tipo MS Outlook, etc.) y acceso vía webmail a estas cuentas. Reenvía del correo a otras cuentas (incluso externas).
Discos duros virtuales que se pueden configurar como unidad de red en un equipo local vía protocolos como
WebDav
Copias de seguridad
Gestión de dominios y subdominios
Estadísticas de tráfico
Asistentes para la instalación rápida de paquetes software libre populares como WordPress, Joomla, etc.
Calidad de servicio y disponibilidad de un servicio de alojamiento web
En un servicio de hosting web es prácticamente imposible garantizar una disponibilidad de servicio del 100%. Por tanto, se suele indicar la disponibilidad del servicio de alojamiento como un parámetro de calidad y nivel de servicio que suele guardar una estrecha relación con el precio del mismo.
La siguiente tabla muestra la traducción de un porcentaje determinado de disponibilidad a la cantidad correspondiente de tiempo que un sistema se encontraría caído por año, mes o semana.
Disponibilidad %Tiempo caídas al añoTiempo caídas al mes*Tiempo caídas por semana
90% 36,5 días 72 horas 16,8 horas
95% 18,25 días 36 horas 8,4 horas
97% 10,96 días 21,6 horas 5,04 horas
98% 7,30 días 14,4 horas 3,36 horas
99% 3,65 días 7,20 horas 1,68 horas
99,5% 1,83 días 3,60 horas 50,4 minutos
99,8% 17,52 horas 86,23 minutos 20,16 minutos
99,9% 8,76 horas 43,2 minutos 10,1 minutos
99,95% 4,38 horas 21,56 minutos 5,04 minutos
99,99% 52,56 minutos 4,32 minutos 1,01 minutos
Dirección IP
Una dirección IP es una etiqueta numérica que identifica, de manera lógica y jerárquica, a un
interfaz (elemento de comunicación/conexión) de un dispositivo (habitualmente una
computadora) dentro de una
red que utilice el
protocolo IP (Internet Protocol), que corresponde al nivel de red del
Modelo OSI. Dicho número no se ha de confundir con la
dirección MAC, que es un identificador de 48bits para identificar de forma única la
tarjeta de red y no depende del protocolo de conexión utilizado ni de la red. La dirección IP puede cambiar muy a menudo por cambios en la red o porque el dispositivo encargado dentro de la red de asignar las direcciones IP decida asignar otra IP (por ejemplo, con el protocolo
DHCP). A esta forma de asignación de dirección IP se denomina también dirección IP dinámica (normalmente abreviado como IP dinámica).
Los sitios de Internet que por su naturaleza necesitan estar permanentemente conectados generalmente tienen una dirección IP fija (comúnmente, IP fija o IP estática). Esta no cambia con el tiempo. Los servidores de correo, DNS, FTP públicos y servidores de páginas web necesariamente deben contar con una dirección IP fija o estática, ya que de esta forma se permite su localización en la red.
Los ordenadores se conectan entre sí mediante sus respectivas direcciones IP. Sin embargo, a los seres humanos nos es más cómodo utilizar otra notación más fácil de recordar, como los
nombres de dominio; la traducción entre unos y otros se resuelve mediante los servidores de nombres de dominio
DNS, que a su vez facilita el trabajo en caso de cambio de dirección IP, ya que basta con actualizar la información en el servidor
DNS y el resto de las personas no se enterarán, ya que seguirán accediendo por el nombre de dominio.
Las direcciones IPv4 se expresan por un número binario de 32 bits, permitiendo un espacio de direcciones de hasta 4.294.967.296 (232) direcciones posibles. Las direcciones IP se pueden expresar como números de notación decimal: se dividen los 32 bits de la dirección en cuatro
octetos. El valor decimal de cada octeto está comprendido en el rango de 0 a 255 [el número binario de 8 bits más alto es 11111111 y esos bits, de derecha a izquierda, tienen valores decimales de 1, 2, 4, 8, 16, 32, 64 y 128, lo que suma 255].
En la expresión de direcciones IPv4 en decimal se separa cada octeto por un carácter único ".". Cada uno de estos octetos puede estar comprendido entre 0 y 255, salvo algunas excepciones. Los ceros iniciales, si los hubiera, se pueden obviar.
Ejemplo de representación de dirección IPv4: 10.128.001.255 o 10.128.1.255
En las primeras etapas del desarrollo del Protocolo de Internet,
1 los administradores de Internet interpretaban las direcciones IP en dos partes, los primeros 8 bits para designar la dirección de red y el resto para individualizar la computadora dentro de la red.
Este método pronto probó ser inadecuado, cuando se comenzaron a agregar nuevas redes a las ya asignadas. En 1981 el direccionamiento internet fue revisado y se introdujo la arquitectura de clases (classful network architecture).
2
En esta arquitectura hay tres clases de direcciones IP que una organización puede recibir de parte de la Internet Corporation for Assigned Names and Numbers (
ICANN): clase A, clase B y clase C.
En una red de clase A, se asigna el primer octeto para identificar la red, reservando los tres últimos octetos (24 bits) para que sean asignados a los hosts, de modo que la cantidad máxima de hosts es 224 - 2 (se excluyen la dirección reservada para broadcast (últimos octetos en 255) y de red (últimos octetos en 0)), es decir, 16.777.214 hosts.
En una red de clase B, se asignan los dos primeros octetos para identificar la red, reservando los dos octetos finales (16 bits) para que sean asignados a los hosts, de modo que la cantidad máxima de hosts es 216 - 2, o 65.534 hosts.
En una red de clase C, se asignan los tres primeros octetos para identificar la red, reservando el octeto final (8 bits) para que sea asignado a los hosts, de modo que la cantidad máxima de hosts es 28 - 2, ó 254 hosts.
ClaseRangoN° de RedesN° de Host Por Red
Máscara de RedBroadcast ID
A 1.0.0.0 - 126.255.255.255 126 16.777.214 255.0.0.0 x.255.255.255
B 128.0.0.0 - 191.255.255.255 16.384 65.534 255.255.0.0 x.x.255.255
C 192.0.0.0 - 223.255.255.255 2.097.152 254 255.255.255.0 x.x.x.255
(D) 224.0.0.0 - 239.255.255.255 histórico
(E) 240.0.0.0 - 255.255.255.255 histórico
La dirección 0.0.0.0 es reservada por la IANA para identificación local.
La dirección que tiene los bits de host iguales a cero sirve para definir la red en la que se ubica. Se denomina dirección de red.
La dirección que tiene los bits correspondientes a host iguales a 255, sirve para enviar paquetes a todos los hosts de la red en la que se ubica. Se denomina dirección de broadcast.
Las direcciones 127.x.x.x se reservan para designar la propia máquina. Se denomina dirección de bucle local o loopback.
El diseño de redes de clases (classful) sirvió durante la expansión de internet, sin embargo este diseño no era escalable y frente a una gran expansión de las redes en la década de los noventa, el sistema de espacio de direcciones de clases fue reemplazado por una arquitectura de redes sin clases
Classless Inter-Domain Routing (CIDR)
3 en el año 1993. CIDR está basada en redes de longitud de máscara de subred variable (variable-length subnet masking VLSM) que permite asignar redes de longitud de prefijo arbitrario. Permitiendo una distribución de direcciones más fina y granulada, calculando las direcciones necesarias y "desperdiciando" las mínimas posibles.
Direcciones privadas
Existen ciertas direcciones en cada clase de dirección IP que no están asignadas y que se denominan
direcciones privadas. Las direcciones privadas pueden ser utilizadas por los hosts que usan traducción de dirección de red (
NAT) para conectarse a una red pública o por los hosts que no se conectan a Internet. En una misma red no pueden existir dos direcciones iguales, pero sí se pueden repetir en dos redes privadas que no tengan conexión entre sí o que se conecten mediante el protocolo NAT. Las direcciones privadas son:
Clase A: 10.0.0.0 a 10.255.255.255 (8 bits red, 24 bits hosts).
Clase B: 172.16.0.0 a 172.31.255.255 (12 bits red, 20 bits hosts). 16 redes clase B contiguas, uso en universidades y grandes compañías.
Clase C: 192.168.0.0 a 192.168.255.255 (16 bits red, 16 bits hosts). 256 redes clase C continuas, uso de compañías medias y pequeñas además de pequeños proveedores de internet (ISP).
Muchas aplicaciones requieren conectividad dentro de una sola red, y no necesitan conectividad externa. En las redes de gran tamaño a menudo se usa TCP/IP. Por ejemplo, los bancos pueden utilizar
TCP/IP para conectar los
cajeros automáticos que no se conectan a la red pública, de manera que las direcciones privadas son ideales para estas circunstancias. Las direcciones privadas también se pueden utilizar en una red en la que no hay suficientes direcciones públicas disponibles.
Las direcciones privadas se pueden utilizar junto con un servidor de traducción de direcciones de red (NAT) para suministrar conectividad a todos los hosts de una red que tiene relativamente pocas direcciones públicas disponibles. Según lo acordado, cualquier tráfico que posea una dirección destino dentro de uno de los intervalos de direcciones privadas no se enrutará a través de Internet.
Máscara de subred
La
máscara permite distinguir los bits que identifican la
red y los que identifican el host de una dirección IP. Dada la dirección de clase A 10.2.1.2 sabemos que pertenece a la red 10.0.0.0 y el
host al que se refiere es el 2.1.2 dentro de la misma. La máscara se forma poniendo a 1 los
bitsque identifican la red y a 0 los bits que identifican el host. De esta forma una dirección de clase
A tendrá como máscara 255.0.0.0, una de clase
B 255.255.0.0 y una de clase
C 255.255.255.0. Los dispositivos de red realizan un
AND entre la dirección IP y la máscara para obtener la dirección de red a la que pertenece el host identificado por la dirección IP dada. Por ejemplo un
router necesita saber cuál es la red a la que pertenece la dirección IP del datagrama destino para poder consultar la
tabla de encaminamiento y poder enviar el
datagrama por la interfaz de salida. Para esto se necesita tener cables directos. La máscara también puede ser representada de la siguiente forma 10.2.1.2/8 donde el /8 indica que los 8 bits más significativos de máscara están destinados a redes, es decir /8 = 255.0.0.0. Análogamente (/16 = 255.255.0.0) y (/24 = 255.255.255.0).
Creación de subredes
El espacio de
direcciones de una red puede ser
subdividido a su vez creando
subredes autónomas separadas. Un ejemplo de uso es cuando necesitamos agrupar todos los empleados pertenecientes a un departamento de una
empresa. En este caso crearíamos una
subred que englobara las direcciones IP de éstos. Para conseguirlo hay que reservar bits del campo host para identificar la subred estableciendo a uno los bits de red-subred en la máscara. Por ejemplo la dirección 172.16.1.1 con máscara 255.255.255.0 nos indica que los dos primeros octetos identifican la red (por ser una dirección de clase B), el tercer octeto identifica la subred (a 1 los bits en la máscara) y el cuarto identifica el host (a 0 los bits correspondientes dentro de la máscara). Hay dos direcciones de cada subred que quedan reservadas: aquella que identifica la subred (campo host a 0) y la dirección para realizar
broadcast en la subred (todos los bits del campo host en 1).
IP dinámica
Una dirección IP dinámica es una IP asignada mediante un servidor
DHCP (Dynamic Host Configuration Protocol) al usuario. La IP que se obtiene tiene una duración máxima determinada. El servidor DHCP provee parámetros de configuración específicos para cada cliente que desee participar en la red
IP. Entre estos parámetros se encuentra la dirección IP del cliente.
DHCP apareció como protocolo estándar en octubre de
1993. El estándar
RFC 2131 especifica la última definición de DHCP (marzo de
1997). DHCP sustituye al protocolo
BOOTP, que es más antiguo. Debido a la compatibilidad retroactiva de DHCP, muy pocas redes continúan usando BOOTP puro.
Las IP dinámicas son las que actualmente ofrecen la mayoría de operadores. El servidor del servicio DHCP puede ser configurado para que renueve las direcciones asignadas cada tiempo determinado.
VentajasReduce los costos de operación a los proveedores de servicios de Internet (
ISP).
Reduce la cantidad de IP asignadas (de forma fija) inactivas.
DesventajasObliga a depender de servicios que redirigen un
host a una IP.
Asignación de direcciones IP
Dependiendo de la implementación concreta, el servidor DHCP tiene tres métodos para asignar las direcciones IP:
manualmente, cuando el servidor tiene a su disposición una tabla que empareja
direcciones MAC con direcciones IP, creada manualmente por el administrador de la red. Sólo clientes con una dirección MAC válida recibirán una dirección IP del servidor.
automáticamente, donde el servidor DHCP asigna por un tiempo pre-establecido ya por el administrador una dirección IP libre, tomada de un rango prefijado también por el administrador, a cualquier cliente que solicite una.
dinámicamente, el único método que permite la re-utilización de direcciones IP. El administrador de la red asigna un rango de direcciones IP para el DHCP y cada ordenador cliente de la
LAN tiene su software de comunicación
TCP/IP configurado para solicitar una dirección IP del servidor DHCP cuando su
tarjeta de interfaz de red se inicie. El proceso es transparente para el usuario y tiene un periodo de validez limitado.
IP fija
Una dirección IP fija es una dirección IP asignada por el usuario de manera manual (Que en algunos casos el ISP o servidor de la red no lo permite), o por el servidor de la red (ISP en el caso de internet, router o switch en caso de LAN) con base en la
Dirección MAC del cliente. Mucha gente confunde
IP Fija con
IP Pública e
IP Dinámica con
IP Privada.
Una IP puede ser Privada ya sea dinámica o fija como puede ser IP Pública Dinámica o Fija.
Una IP pública se utiliza generalmente para montar servidores en internet y necesariamente se desea que la IP no cambie por eso siempre la IP Pública se la configura de manera Fija y no Dinámica, aunque si se podría.
En el caso de la IP Privada generalmente es dinámica asignada por un servidor DHCP, pero en algunos casos se configura IP Privada Fija para poder controlar el acceso a internet o a la red local, otorgando ciertos privilegios dependiendo del número de IP que tenemos, si esta cambiara (fuera dinámica) sería más complicado controlar estos privilegios (pero no imposible).
* Cómo se utiliza la información. El Director del Programa puede necesitar combinar datos clínicos y financieros para establecer el costo-efectividad de los servicios que se ofrecen
* Qué nivel de detalle se requiere. El agente que ofrece servicios de PF puede necesitar información muy detallada sobre el status de cada cliente.
* Qué formato debe utilizarse para presentar la información (tablas, gráficas, informes). El Director Regional del Programa puede requerir tablas que resuman la información de los usuarios regulares por distrito, para comparar la cobertura de los agentes que ofrecen los servicios en esa región.
Cuando la información va de un usuario a otro, cambiará tanto el nivel de detalle como el formato en que se presenta. Estos cambios en detalle y formato (palabras, tablas numéricas y gráficas) deben corresponder a las necesidades del usuario y al nivel en el que se utilizará la información.
Cómo hacer para ...
Crear una gráfica del flujo de la información
Para asegurar que la información esté circulando como se requiere, puede prepararse una tabla de flujo de la información. Esta tabla muestra al personal que requerirá utilizar la información, cómo será utilizada por cada miembro del personal, qué tan detallada necesita ser y qué informes se harán con la información que se planea recolectar.
Esta tabla ayudará a verificar si la información está circulando apropiadamente, a descubrir qué problemas de flujo de información existen y a decidir qué hacer para mejorar la situación. Esta tabla puede actualizarse continuamente para ver cómo cambia el flujo de información mientras el programa evoluciona y cómo cambian las necesidades de información.
Cómo recolectar información
Selección de instrumentos para la recolección de datos
Después de seleccionar los indicadores apropiados, identificar las fuentes de información y considerar cómo circulará la información entre el personal, se puede pasar a revisar los instrumentos y procedimientos para la recolección de datos. Se requiere de un gran esfuerzo para obtener información y, por lo tanto, es importante asegurar que tanto la recolección como el uso sean lo menos complicado posible.
Los datos de rutina se obtienen de diferentes fuentes utilizando distintos tipos de instrumentos de recolección. Los tipos de instrumentos requeridos dependen de la información que se necesite recoger.
Todos los instrumentos de recolección de datos deben ser considerados como un paquete de herramientas interrelacionadas que ayudan a los administradores a obtener la información que necesitan para tomar decisiones adecuadas.
Herramientas y Técnicas - Instrumentos de recolección de datos de rutina y sus usos
Cómo hacer para ...
Mejorar la recolección de información de rutina
Es importante examinar los registros, archivos y formularios para ver si proporcionan la información que se necesita. Igualmente conviene identificar las formas de registro que requieren mejoras y realizarlas en coordinación con el personal.
Si se necesita crear un nuevo archivo, es necesario asegurarse que el diseño de los formularios facilite el registro y tabulación de la información de manera exacta. Muchos formularios tienden a comprimir una gran cantidad de información en una sola hoja de papel. El resultado que se obtiene es un registro generalmente ilegible. Si los instrumentos para la recolección de datos son ilegibles, la información será ignorada porque el personal no tiene tiempo para tratar de descifrar la escritura. Por lo tanto se pierde tiempo en llenar el formulario y se desperdicia la información.
el weblog,
UN nuevo flujo de información
Los weblogs se presentan aquí como un nuevo paso en un emergente y auto-organizado flujo de información, característico de nuestro mundo post-web. El 11 de septiembre los weblogs pasan al primer plano y se convierten en parte de la evolución de los media. Aparte de este rasgo periodístico característico, el fenómeno comunicativo de los weblogs se extiende más allá, y se relaciona con el movimiento de programación colectiva (código abierto/software libre) y el nuevo modelo para la producción, publicación y acceso a la ciencia. La web editable, anunciada por la inminente web semántica, adquiere un significado concreto con los weblogs. En este nuevo flujo de información, los blogs están interviniendo activamente como neuronas con sinapsis que se multiplican en el cerebro planetario.
Estructura de Internet
Internet no es una red centralizada ni está regida por un solo organismo. Su estructura se parece a una tela de araña en la cual unas redes se conectan con otras. No obstante hay una serie de organizaciones responsables de la adjudicación de recursos y el desarrollo de los protocolos necesarios para que
Internet evolucione. Por ejemplo:
la
Internet Engineering Task Force (IETF) se encarga de redactar los protocolos usados en
Internet.
la
Corporación de Internet para la Asignación de Nombres y Números (ICANN) es la autoridad que coordina la asignación de identificadores únicos en Internet, incluyendo
nombres de dominio,
direcciones IP, etc.
Las direcciones en Internet
En
Internet se emplean varios formatos para identificar máquinas, usuarios o recursos en general.
En
Internet se emplean direcciones numéricas para identificar máquinas: las
direcciones IP. Se representan por cuatro números, de 0 a 255, separados por puntos. Un servidor puede identificarse, por ejemplo, con la dirección IP 66.230.200.100. Como es más sencillo recordar un nombre, las direcciones se "traducen" a nombres. Los trozos "traducidos" se denominan nombres de dominio. El servicio encargado de la traducción es el
DNS e identifica las numeraciones de los usuarios conectados
Para identificar a usuarios de correo electrónico se emplean las direcciones de correo electrónico, que tienen el siguiente formato:usuario@servidor_de_correo.dominio
Para identificar recursos en
Internet, se emplean direcciones
URL (Uniform Resource Locator, Localizador Uniforme de Recursos). Una dirección
URL tiene la forma:http://nombre_de_empresa.dominio/abc.htm
Siendo "http://" el protocolo, "nombre_de_empresa.dominio" el dominio (que es trasladado a una dirección IP por el servicios DNS), y "abc.htm" la localización del recurso al que se accede.
El flujo de información en Internet[
editar ·
editar fuente]
La arquitectura cliente-servidor[
editar ·
editar fuente]
El procedimiento empleado para intercambiar información en Internet sigue el modelo cliente-servidor.
Los servidores son computadoras donde se almacenan datos.
El cliente es la computadora que realiza la petición al servidor para que éste le muestre alguno de los recursos almacenados.
Los paquetes de información[
editar ·
editar fuente]
En Internet la información se transmite en pequeños trozos llamados "
paquetes". Lo importante es la reconstrucción en el destino del mensaje emitido, no el camino seguido por los paquetes que lo componen.
Si se destruye un nodo de la red, los paquetes encontrarán caminos alternativos. Este procedimiento no es el más eficiente, pero resiste las averías de una parte de la red.
Protocolo TCP/IP[
editar ·
editar fuente]
Para intercambiar información entre computadores es necesario desarrollar técnicas que regulen la transmisión de paquetes. Dicho conjunto de normas se denomina protocolo. Hacia
1973 aparecieron los protocolos
TCP e
IP, utilizados ahora para controlar el flujo de datos en
Internet.
El protocolo TCP (y también el
UDP), se encarga de fragmentar el mensaje emitido en paquetes. En el destino, se encarga de reorganizar los paquetes para formar de nuevo el mensaje, y entregarlo a la aplicación correspondiente.
El
protocolo IP enruta los paquetes. Esto hace posible que los distintos paquetes que forman un mensaje pueden viajar por caminos diferentes hasta llegar al destino.
La unión de varias redes (
ARPANET y otras) en
Estados Unidos, en
1983, siguiendo el
protocolo TCP/IP, puede ser considerada como el nacimiento de
Internet (Interconnected Networks[
cita requerida]).
Servicio de Nombres[
editar ·
editar fuente]
Existe un servicio que se encarga de proporcionar la correspondencia entre una
dirección IP y su nombre de dominio, y viceversa. Este servicio es el
DNS (Domain Name System, Sistema de Nombres de Dominio).
Cada vez que se inicia una comunicación con un nombre de dominio, el ordenador realiza una petición a su servidor
DNS para que le proporcione la
IP asociada a ese nombre.
El sistema
DNS es jerárquico. Cada subdominio de Internet suele tener su propio servidor
DNS, responsable de los nombres bajo su dominio. A su vez, hay un servidor encargado de cada dominio (por ejemplo un nivel nacional (.es)), y hay una serie de servidores raíz, que conocen'toda la estructura de
El funcionamiento del correo electrónico[
editar ·
editar fuente]
Artículo principal:
Correo electrónico.
Los primeros mensajes de correo electrónico solo incluían texto
ASCII. Luego se crearon las extensiones
MIME al
protocolo SMTP, para poder enviar mensajes con archivos adjuntos, utilizar otros juegos de caracteres, o p. ej. enviar un mensaje con formato
HTML.
El proceso de envío es el siguiente (se indica entre paréntesis el protocolo utilizado en cada paso):
Cuando un usuario envía un correo, el mensaje se dirige hasta el servidor encargado del envío de correo electrónico de su proveedor de Internet (
SMTP).
Este servidor lo reenvía al servidor de correo electrónico encargado de la recepción de mensajes del destinatario (
SMTP).
El servidor de correo electrónico del destinatario procesa el mensaje y lo deposita en el buzón del destinatario. El mensaje ha llegado.
Este buzón es accesible mediante el servidor de lectura de correos (
POP, ó
IMAP). Así, cuando el destinatario, posteriormente, solicita sus mensajes, el servidor de correo de lectura se los envía. Ahora, el destinatario puede leerlos.
Todo este proceso (pasos del 1 al 3) se realiza en un período breve. Pocos minutos (o solamente segundos), bastan, en general, para que llegue el mensaje hasta su destino. Factores derivados del tráfico en las redes, filtros
antispam y
antivirus, y otros, pueden influir en este tiempo.
Nota: Esto no se aplica para cuentas de correo en yahoo, hotmail y otros, pues se procesan como flujo de información dentro de Internet. Esto se aplica cuando se utilizan las cuentas de correo proporcionado por los proveedores de Internet (IPs - en inglés).
Protocolos de correo electrónico[
editar ·
editar fuente]
El protocolo
SMTP (Simple Mail Transfer Protocol) permite el envío (correo saliente) desde el cliente hacia
Internet (el mensaje se transmite, inicialmente, entre servidores de correo).
El protocolo
POP (Post Office Protocol) permite recibir mensajes de correo hacia el cliente (se almacenan en el ordenador del destinatario), desde el servidor (correo entrante).
El protocolo
IMAP (Internet Message Access Protocol) permite recibir mensajes de correo hacia el cliente (se almacenan en el ordenador del destinatario), desde el servidor, al igual que el protocolo POP (correo entrante), pero IMAP permite que se pueda gestionar el correo de forma más flexible. Así, es posible sincronizar contenidos entre el cliente y el servidor, utilizar diferentes carpetas para clasificar el correo (sincronizadas entre cliente y servidor), realizar búsquedas en el lado del servidor, descargar solamente partes del mensaje, etc...
Paquete de redSe le llama paquete de red o paquete de datos a cada uno de los bloques en que se divide, en el nivel de Red, la información a enviar. Por debajo del nivel de red se habla de
trama de red, aunque el concepto es análogo.
En todo sistema de comunicaciones resulta interesante dividir la información a enviar en bloques de un tamaño máximo conocido. Esto simplifica el control de la comunicación, las comprobaciones de errores, la gestión de los equipos de encaminamiento (
routers), etc.
Un paquete de datos es una unidad fundamental de transporte de información en todas las
redes de computadoras modernas. Un paquete está generalmente compuesto de tres elementos: una cabecera (header en inglés) que contiene generalmente la información necesaria para trasladar el paquete desde el emisor hasta el receptor, el área de datos (payload en inglés) que contiene los
datos que se desean trasladar, y la cola (trailer en inglés), que comúnmente incluye código de detección de errores.
Estructura
Al igual que las tramas, los paquetes pueden estar formados por una cabecera, una parte de datos y una cola. En la cabecera estarán los campos que pueda necesitar el protocolo de nivel de red, en la cola, si la hubiere, se ubica normalmente algún mecanismo de comprobación de errores.
Dependiendo de que sea una red de
datagramas o de
circuitos virtuales (CV), la cabecera del paquete contendrá la dirección de las estaciones de origen y destino o el identificador del CV. En las redes de datagramas no suele haber cola, porque no se comprueban errores, quedando esta tarea para el nivel de transporte.
Ejemplo: paquete de
IP[
editar ·
editar código]
Actualmente se considera que un paquete corresponde a la capa de red del
Modelo OSI, por ejemplo en el caso del
protocolo IP. Siendo el paquete la unidad de datos de protocolo (
PDU) de la capa de red.
Por lo general, cada capa emisora de un protocolo toma la PDU de una capa superior, y lo codifica dentro del área de datos. A medida que se transmite, la capa recibe la PDU de su capa par, recupera el área de datos y la transmite a una capa superior, que procede de igual manera. Por esto, las PDU tiene encapsuladas en su area de datos otras PDU.
El protocolo de red
IP sólo tiene cabecera, ya que no realiza ninguna comprobación sobre el contenido del paquete. Sus campos se representan siempre alineados en múltiplos de 32 bits. Los campos son, por este orden:
Versión: 4 bits, actualmente se usa la versión 4, aunque ya esta en funcionamiento la
versión 6. Este campo permite a los routers discriminar si pueden tratar o no el paquete.
Longitud de cabecera (IHL): 4 bits, indica el número de palabras de 32 bits que ocupa la cabecera. Esto es necesario porque la cabecera puede tener una longitud variable.
Tipo de servicio: 6 bits (+2 bits que no se usan), en este campo se pensaba recoger la prioridad del paquete y el tipo de servicio deseado, pero los routers no hacen mucho caso de esto y en la práctica no se utiliza. Los tipos de servicios posibles serían:
D: (Delay) Menor retardo, por ejemplo para audio o vídeo.
T: (Throughput) Mayor velocidad, por ejemplo para envío de ficheros grandes.
R: (Reliability) Mayor fiabilidad, para evitar en la medida de lo posible los reenvíos.
Longitud del paquete: 16 bits, como esto lo incluye todo, el paquete más largo que puede enviar IP es de 65535 bytes, pero la carga útil será menor, porque hay que descontar lo que ocupa la propia cabecera.
Identificación: 16 bits, Es un número de serie del paquete, si un paquete se parte en pedazos más pequeños por el camino (se fragmenta) cada uno de los fragmentos llevará el mismo número de identificación.
control de fragmentación: son 16 bits que se dividen en:
1 bit vacío: sobraba sitio.
1 bit DF: del ínglés dont't fragment. Si vale 1 le advierte al router que este paquete no se corta.
1 bit MF: del inglés more fragments indica que éste es un fragmento de un paquete más grande y que, además, no es el último fragmento.
desplazamiento de Fragmento: es la posición en la que empieza este fragmento respecto del paquete original.
Tiempo de vida: 8 bits, en realidad se trata del número máximo de routers (o de saltos) que el paquete puede atravesar antes de ser descartado. Como máximo 255 saltos.
Protocolo: 8 bits, este campo codifica el protocolo de nivel de transporte al que va destinado este paquete. Está unificado para todo el mundo en
Números de protocolos por la
IANA Internet Assigned Numbers Authority.
Checksum de la cabecera: 16 bits, aunque no se comprueben los datos, la integridad de la cabecera sí es importante, por eso se comprueba.
Direcciones de origen y destino: 32 bits cada una. Son las
direcciones IP de la estaciones de origen y destino.
Opciones: Esta parte puede estar presente o no, de estarlo su longitud máxima es de 40 bytes.
Familia de protocolos de InternetLa familia de protocolos de Internet es un conjunto de
protocolos de red en los que se basa
Internet y que permiten la transmisión de datos entre
computadoras. En ocasiones se le denomina conjunto de protocolos TCP/IP, en referencia a los dos protocolos más importantes que la componen:
Protocolo de Control de Transmisión (TCP) y
Protocolo de Internet (IP), que fueron dos de los primeros en definirse, y que son los más utilizados de la familia. Existen tantos protocolos en este conjunto que llegan a ser más de 100 diferentes, entre ellos se encuentra el popular
HTTP (HyperText Transfer Protocol), que es el que se utiliza para acceder a las
páginas web, además de otros como el
ARP (Address Resolution Protocol) para la resolución de direcciones, el
FTP (File Transfer Protocol) para transferencia de archivos, y el
SMTP (Simple Mail Transfer Protocol) y el
POP (Post Office Protocol) para
correo electrónico,
TELNET para acceder a equipos remotos, entre otros.
El TCP/IP es la base de
Internet, y sirve para enlazar
computadoras que utilizan diferentes
sistemas operativos, incluyendo
PC,
minicomputadoras y computadoras centrales sobre redes de área local (
LAN) y área extensa (
WAN).
TCP/IP fue desarrollado y demostrado por primera vez en
1972 por el
Departamento de Defensa de los
Estados Unidos, ejecutándolo en
ARPANET, una red de área extensa de dicho departamento.
La familia de protocolos de Internet puede describirse por
analogía con el
modelo OSI (Open System Interconnection), que describe los niveles o capas de la pila de protocolos, aunque en la práctica no corresponde exactamente con el modelo en Internet. En una pila de protocolos, cada nivel resuelve una serie de tareas relacionadas con la transmisión de datos, y proporciona un servicio bien definido a los niveles más altos. Los niveles superiores son los más cercanos al usuario y tratan con datos más abstractos, dejando a los niveles más bajos la labor de traducir los datos de forma que sean físicamente manipulables.
El modelo de Internet fue diseñado como la solución a un problema práctico de ingeniería.
El
modelo OSI, en cambio, fue propuesto como una aproximación teórica y también como una primera fase en la evolución de las
redes de ordenadores. Por lo tanto, el
modelo OSI es más fácil de entender, pero el modelo TCP/IP es el que realmente se usa. Sirve de ayuda entender el
modelo OSI antes de conocer TCP/IP, ya que se aplican los mismos principios, pero son más fáciles de entender en el
modelo OSI.
El protocolo TCP/IP es el sucesor del
NCP, con el que inició la operación de ARPANET, y fue presentado por primera vez con los RFCs 791,
1 792
2 y 793
3 en septiembre de
1981. Para noviembre del mismo año se presentó el plan definitivo de transición en el
RFC 8014 , y se marcó el
1 de enero de
1983 como el Día Bandera para completar la migración.
Índice [
mostrar]
Historia del Protocolo TCP/IP[
editar ·
editar código]
La Familia de Protocolos de Internet fueron el resultado del trabajo llevado a cabo por la Agencia de Investigación de Proyectos Avanzados de Defensa (DARPA por sus siglas en inglés) a
principios de los 70. Después de la construcción de la pionera
ARPANET en
1969 DARPA comenzó a trabajar en un gran número de tecnologías de transmisión de datos. En 1972,
Robert E. Kahn fue contratado por la Oficina de Técnicas de Procesamiento de Información de DARPA, donde trabajó en la comunicación de
paquetes por
satélite y por
ondas de radio, reconoció el importante valor de la comunicación de estas dos formas. En la primavera de 1973,
Vint Cerf, desarrollador del protocolo de ARPANET, Network Control Program(NPC) se unió a Kahn con el objetivo de crear una arquitectura abierta de interconexión y diseñar así la nueva generación de protocolos de ARPANET.
Para el verano de
1973, Kahn y Cerf habían conseguido una remodelación fundamental, donde las diferencias entre los protocolos de red se ocultaban usando un
Protocolo de comunicaciones y además, la red dejaba de ser responsable de la fiabilidad de la comunicación, como pasaba en ARPANET, era el
host el responsable. Cerf reconoció el mérito de
Hubert Zimmerman y
Louis Pouzin, creadores de la
red CYCLADES, ya que su trabajo estuvo muy influenciado por el diseño de esta red.
Con el papel que realizaban las redes en el proceso de comunicación reducido al mínimo, se convirtió en una posibilidad real comunicar redes diferentes, sin importar las características que éstas tuvieran. Hay un dicho popular sobre el protocolo TCP/IP, que fue el producto final desarrollado por Cerf y Kahn, que dice que este protocolo acabará funcionando incluso entre "dos latas unidas por un cordón". De hecho hay hasta una implementación usando
palomas mensajeras,
IP sobre palomas mensajeras, que está documentado en
RFC 1149.
5 6
Un ordenador denominado router (un nombre que fue después cambiado a gateway, puerta de enlace, para evitar confusiones con otros tipos de
Puerta de enlace) está dotado con una interfaz para cada red, y envía
Datagramas de ida y vuelta entre ellos. Los requisitos para estos routersestán definidos en el
RFC 1812.
7
Esta idea fue llevada a la práctica de una forma más detallada por el grupo de investigación que Cerf tenía en
Stanford durante el periodo de 1973 a 1974, dando como resultado la primera especificación TCP (
Request for Comments 675,)
8 Entonces DARPA fue contratada por
BBN Technologies, la
Universidad de Stanford, y la
University College de Londres para desarrollar versiones operacionales del protocolo en diferentes plataformas de hardware. Se desarrollaron así cuatro versiones diferentes: TCP v1, TCP v2, una tercera dividida en dos TCP v3 y IP v3 en la primavera de 1978, y después se estabilizó la versión TCP/IP v4 — el protocolo estándar que todavía se emplea en Internet.
En
1975, se realizó la primera prueba de comunicación entre dos redes con protocolos TCP/IP entre la Universidad de Stanford y la University College de
Londres (UCL). En
1977, se realizó otra prueba de comunicación con un protocolo TCP/IP entre tres redes distintas con ubicaciones en
Estados Unidos,
Reino Unido y
Noruega. Varios prototipos diferentes de protocolos TCP/IP se desarrollaron en múltiples centros de investigación entre los años
1978 y
1983. La migración completa de la red
ARPANET al protocolo TCP/IP concluyó oficialmente el día
1 de enero de
1983cuando los protocolos fueron activados permanentemente.
9
En marzo de
1982, el
Departamento de Defensa de los Estados Unidos declaró al protocolo TCP/IP el estándar para las comunicaciones entre redes militares.
10 En
1985, el Centro de Administración de Internet (Internet Architecture Board IAB por sus siglas en inglés) organizó un Taller de Trabajo de tres días de duración, al que asistieron 250 comerciales promocionando así el protocolo lo que contribuyó a un incremento de su uso comercial.
Kahn y Cerf fueron premiados con la
Medalla Presidencial de la Libertad el
10 de noviembre de
2005 por su contribución a la cultura estadounidense.
11
Ventajas e inconvenientes[
editar ·
editar código]
El conjunto TCP/IP está diseñado para enrutar y tiene un grado muy elevado de fiabilidad, es adecuado para redes grandes y medianas, así como en redes empresariales. Se utiliza a nivel mundial para conectarse a
Internet y a los servidores web. Es compatible con las herramientas estándar para analizar el funcionamiento de la red.
Un inconveniente de TCP/IP es que es más difícil de configurar y de mantener que
NetBEUI o
IPX/SPX; además es algo más lento en redes con un volumen de tráfico medio bajo. Sin embargo, puede ser más rápido en redes con un volumen de tráfico grande donde haya que enrutar un gran número de tramas.
El conjunto TCP/IP se utiliza tanto en campus universitarios como en complejos empresariales, en donde utilizan muchos enrutadores y conexiones a mainframe o a ordenadores
UNIX, así como también en redes pequeñas o domésticas, en
teléfonos móviles y en
domótica.
Gracias a que el conjunto de protocolos TCP/IP no pertenecía a una empresa en concreto y permitir el Departamento de Defensa de los EE.UU. su uso por parte de cualquier fabricante, fue lo que permitió el nacimiento de Internet como lo conocemos hoy. Los fabricantes fueron abandonando poco a poco sus protocolos propios de comunicaciones y adoptando TCP/IP.
File Transfer Protocol
File Transfer Protocol
(FTP)
Familia
Familia de protocolos de Internet
Función protocolo de transferencia de archivos
Puertos 20/TCP DATA Port
21/TCP Control Port
Ubicación en la pila de protocolos
Aplicación FTP
Transporte TCP
Red IP
Estándares
FTP:
RFC 959 (
1985)
Extensiones de FTP para IPv6 y NATs:
RFC 2428 (
1998)
FTP (
siglas en
inglés de File Transfer Protocol, 'Protocolo de Transferencia de Archivos') en informática, es un
protocolo de red para la
transferencia de archivos entre sistemas conectados a una red
TCP (Transmission Control Protocol), basado en la arquitectura
cliente-servidor. Desde un equipo cliente se puede conectar a un servidor para descargar archivos desde él o para enviarle archivos, independientemente del sistema operativo utilizado en cada equipo.
El servicio FTP es ofrecido por la capa de aplicación del modelo de capas de red
TCP/IP al usuario, utilizando normalmente el
puerto de red 20 y el 21. Un problema básico de FTP es que está pensado para ofrecer la máxima velocidad en la conexión, pero no la máxima seguridad, ya que todo el intercambio de información, desde el login y password del usuario en el servidor hasta la transferencia de cualquier archivo, se realiza en
texto plano sin ningún tipo de cifrado, con lo que un posible atacante puede capturar este tráfico, acceder al servidor y/o apropiarse de los archivos transferidos.
Para solucionar este problema son de gran utilidad aplicaciones como
scp y sftp, incluidas en el paquete
SSH, que permiten transferir archivos pero
cifrando todo el tráfico.
Índice [
mostrar]
El Modelo FTP
El siguiente modelo representa el diagrama de un servicio FTP.
En el modelo, el intérprete de protocolo (IP) de usuario inicia la conexión de control en el
puerto 21. Las órdenes FTP estándar las genera el IP de usuario y se transmiten al proceso servidor a través de la conexión de control. Las respuestas estándar se envían desde la IP del servidor la IP de usuario por la conexión de control como respuesta a las órdenes.
Estas órdenes FTP especifican parámetros para la conexión de datos (puerto de datos, modo de transferencia, tipo de representación y estructura) y la naturaleza de la operación sobre el
sistema de archivos (almacenar, recuperar, añadir, borrar, etc.). El proceso de transferencia de datos (DTP) de usuario u otro proceso en su lugar, debe esperar a que el servidor inicie la conexión al puerto de datos especificado (puerto 20 en modo activo o estándar) y transferir los datos en función de los parámetros que se hayan especificado.
Vemos también en el diagrama que la comunicación entre
cliente y
servidor es independiente del sistema de archivos utilizado en cada
computadora, de manera que no importa que sus sistemas operativos sean distintos, porque las entidades que se comunican entre sí son los PI y los DTP, que usan el mismo protocolo estandarizado: el FTP.
También hay que destacar que la conexión de datos es bidireccional, es decir, se puede usar simultáneamente para enviar y para recibir, y no tiene por qué existir todo el tiempo que dura la conexión FTP. Pero tenía en sus comienzos un problema, y era la localización de los servidores en la red. Es decir, el usuario que quería descargar algún archivo mediante FTP debía conocer en qué máquina estaba ubicado. La única herramienta de búsqueda de información que existía era Gopher, con todas sus limitaciones.
Primer buscador de información[
editar ·
editar fuente]
Gopher significa 'lanzarse sobre' la información. Es un servicio cuyo objetivo es la localización de archivos a partir de su título. Consiste en un conjunto de menús de recursos ubicados en diferentes máquinas que están intercomunicadas. Cada máquina sirve una área de información, pero su organización interna permite que todas ellas funcionen como si se tratase de una sola máquina. El usuario navega a través de estos menús hasta localizar la información buscada, y desconoce exactamente de qué máquina está descargando dicha información. Con la llegada de Internet, los potentes motores de búsqueda (Google) dejaron el servicio Gopher, y la localización de los servidores FTP dejó de ser un problema. En la actualidad, cuando el usuario se descarga un archivo a partir de un enlace de una página web no llega ni a saber que lo está haciendo desde un servidor FTP. El servicio FTP ha evolucionado a lo largo del tiempo y hoy día es muy utilizado en Internet, en redes corporativas, Intranets, etc. Soportado por cualquier sistema operativo, existe gran cantidad de software basado en el protocolo FTP.
Servidor FTP
Un servidor FTP es un programa especial que se ejecuta en un equipo servidor normalmente conectado a Internet (aunque puede estar conectado a otros tipos de redes,
LAN,
MAN, etc.). Su función es permitir el intercambio de datos entre diferentes servidores/ordenadores.
Por lo general, los programas servidores FTP no suelen encontrarse en los ordenadores personales, por lo que un usuario normalmente utilizará el FTP para conectarse remotamente a uno y así intercambiar información con él.
Las aplicaciones más comunes de los servidores FTP suelen ser el
alojamiento web, en el que sus clientes utilizan el servicio para subir sus páginas web y sus archivos correspondientes; o como servidor de backup (copia de seguridad) de los archivos importantes que pueda tener una empresa. Para ello, existen protocolos de comunicación FTP para que los datos se transmitan cifrados, como el
SFTP (Secure File Transfer Protocol).
Cliente FTP[
editar ·
editar fuente]
Cuando un navegador no está equipado con la función FTP, o si se quiere cargar archivos en un ordenador remoto, se necesitará utilizar un programa cliente FTP. Un cliente FTP es un programa que se instala en el ordenador del usuario, y que emplea el protocolo FTP para conectarse a un servidor FTP y transferir archivos, ya sea para descargarlos o para subirlos.
Para utilizar un cliente FTP, se necesita conocer el nombre del archivo, el ordenador en que reside (servidor, en el caso de descarga de archivos), el ordenador al que se quiere transferir el archivo (en caso de querer subirlo nosotros al servidor), y la carpeta en la que se encuentra.
Algunos clientes de FTP básicos en modo consola vienen integrados en los
sistemas operativos, incluyendo
Microsoft Windows,
DOS,
GNU/Linux y
Unix. Sin embargo, hay disponibles clientes con opciones añadidas e interfaz gráfica. Aunque muchos navegadores tienen ya integrado FTP, es más confiable a la hora de conectarse con servidores FTP no anónimos utilizar un programa cliente.
Acceso anónimo
Los servidores FTP anónimos ofrecen sus servicios libremente a todos los usuarios, permiten acceder a sus archivos sin necesidad de tener un 'USER ID' o una cuenta de usuario. Es la manera más cómoda fuera del servicio web de permitir que todo el mundo tenga acceso a cierta información sin que para ello el administrador de un sistema tenga que crear una cuenta para cada usuario.
Si un servidor posee servicio 'FTP anonymous' solamente con teclear la palabra «anonymous», cuando pregunte por tu usuario tendrás acceso a ese sistema. No se necesita ninguna contraseña preestablecida, aunque tendrás que introducir una sólo para ese momento, normalmente se suele utilizar la dirección de correo electrónico propia.
Solamente con eso se consigue acceso a los archivos del FTP, aunque con menos privilegios que un usuario normal. Normalmente solo podrás leer y copiar los archivos que sean públicos, así indicados por el administrador del servidor al que nos queramos conectar.
Normalmente, se utiliza un servidor FTP anónimo para depositar grandes archivos que no tienen utilidad si no son transferidos a la máquina del usuario, como por ejemplo programas, y se reservan los servidores de páginas web (HTTP) para almacenar información textual destinada a la lectura en línea.
Acceso de usuario
Si se desea tener privilegios de acceso a cualquier parte del sistema de archivos del servidor FTP, de modificación de archivos existentes, y de posibilidad de subir nuestros propios archivos, generalmente se suele realizar mediante una cuenta de usuario. En el servidor se guarda la información de las distintas cuentas de usuario que pueden acceder a él, de manera que para iniciar una sesión FTP debemos introducir una
autentificación (en
inglés: login) y una
contraseña (en inglés: password) que nos identifica unívocamente.
Cliente FTP basado en Web[
editar ·
editar fuente]
Un «cliente FTP basado en Web» no es más que un cliente FTP al cual podemos acceder a través de nuestro navegador web sin necesidad de tener otra aplicación para ello. El usuario accede a un servidor web (HTTP) que lista los contenidos de un servidor FTP. El usuario se conecta mediante HTTP a un servidor web, y el servidor web se conecta mediante FTP al servidor FTP. El servidor web actúa de intermediario haciendo pasar la información desde el servidor FTP en los puertos 20 y 21 hacia el puerto 80 HTTP que ve el usuario.
Siempre hay momentos en que nos encontramos fuera de casa, no llevamos el ordenador portátil encima y necesitamos realizar alguna tarea urgente desde un ordenador de acceso público, de un amigo, del trabajo, la universidad, etc. Lo más común es que no estén instaladas las aplicaciones que necesitamos y en muchos casos hasta carecemos de los permisos necesarios para realizar su instalación. Otras veces estamos detrás de un proxy o cortafuegos que no nos permite acceder a servidores FTP externos.
Al disponer de un cliente FTP basado en Web podemos acceder al servidor FTP remoto como si estuviéramos realizando cualquier otro tipo de navegación web. A través de un cliente FTP basado en Web podrás, crear, copiar, renombrar y eliminar archivos y directorios. Cambiar permisos, editar, ver, subir y descargar archivos, así como cualquier otra función del protocolo FTP que el servidor FTP remoto permita.
Acceso de invitado
El acceso sin restricciones al servidor que proporcionan las cuentas de usuario implica problemas de seguridad, lo que ha dado lugar a un tercer tipo de acceso FTP denominado invitado (guest), que se puede contemplar como una mezcla de los dos anteriores.
La idea de este mecanismo es la siguiente: se trata de permitir que cada usuario conecte a la máquina mediante su login y su password, pero evitando que tenga acceso a partes del sistema de archivos que no necesita para realizar su trabajo, de esta forma accederá a un entorno restringido, algo muy similar a lo que sucede en los accesos anónimos, pero con más privilegios.
Modos de conexión del cliente FTP
FTP admite dos modos de conexión del cliente. Estos modos se denominan activo (o Estándar, o PORT, debido a que el cliente envía comandos tipo PORT al servidor por el canal de control al establecer la conexión) y pasivo (o PASV, porque en este caso envía comandos tipo PASV). Tanto en el modo Activo como en el modo Pasivo, el cliente establece una conexión con el servidor mediante el puerto 21, que establece el canal de control.
Modo activo[
editar ·
editar fuente]
Modo activo.
En modo Activo, el servidor siempre crea el canal de datos en su puerto 20, mientras que en el lado del cliente el canal de datos se asocia a un puerto aleatorio mayor que el 1024. Para ello, el cliente manda un comando PORT al servidor por el canal de control indicándole ese número de puerto, de manera que el servidor pueda abrirle una conexión de datos por donde se transferirán los archivos y los listados, en el puerto especificado.
Lo anterior tiene un grave problema de seguridad, y es que la máquina cliente debe estar dispuesta a aceptar cualquier conexión de entrada en un puerto superior al 1024, con los problemas que ello implica si tenemos el equipo conectado a una red insegura como Internet. De hecho, los
cortafuegos que se instalen en el equipo para evitar ataques seguramente rechazarán esas conexiones aleatorias. Para solucionar esto se desarrolló el modo pasivo.
Modo pasivo
Modo pasivo.
Cuando el cliente envía un comando PASV sobre el canal de control, el servidor FTP le indica por el canal de control, el puerto (mayor a 1023 del servidor. Ejemplo:2040) al que debe conectarse el cliente. El cliente inicia una conexión desde el puerto siguiente al puerto de control (Ejemplo: 1036) hacia el puerto del servidor especificado anteriormente (Ejemplo: 2040).
1
Antes de cada nueva transferencia tanto en el modo Activo como en el Pasivo, el cliente debe enviar otra vez un comando de control (PORT o PASV, según el modo en el que haya conectado), y el servidor recibirá esa conexión de datos en un nuevo puerto aleatorio (si está en modo pasivo) o por el puerto 20 (si está en modo activo). En el protocolo FTP existen 2 tipos de transferencia en ASCII y en binarios.
Tipos de transferencia de archivos en FTP
Es importante conocer cómo debemos transportar un archivo a lo largo de la red. Si no utilizamos las opciones adecuadas podemos destruir la información del archivo. Por eso, al ejecutar la aplicación FTP, debemos acordarnos de utilizar uno de estos comandos (o poner la correspondiente opción en un programa con interfaz gráfica):
Tipo ASCII
Adecuado para transferir archivos que sólo contengan caracteres imprimibles (archivos ASCII, no archivos resultantes de un procesador de texto), por ejemplo páginas HTML, pero no las imágenes que puedan contener.
Tipo Binario
Este tipo es usado cuando se trata de archivos comprimidos, ejecutables para PC, imágenes, archivos de audio...
Ejemplos de cómo transferir algunos tipos de archivo dependiendo de su extensión:
Extensión de archivoTipo de transferencia
txt (texto) ascii
html (página WEB) ascii
doc (documento) binario
ps (poscript) ascii
hqx (comprimido) ascii
Z (comprimido) binario
ZIP (comprimido) binario
ZOO (comprimido) binario
Sit (comprimido) binario
pit (comprimido) binario
shar (comprimido) binario
uu (comprimido) binario
ARC (comprimido) binario
tar (empaquetado) binario
Correo electrónico
Principalmente se usa este nombre para denominar al sistema que provee este servicio en
Internet, mediante el protocolo
SMTP, aunque por extensión también puede verse aplicado a sistemas análogos que usen otras tecnologías. Por medio de mensajes de correo electrónico se puede enviar, no solamente texto, sino todo tipo de documentos digitales dependiendo del sistema que se use. Su eficiencia, conveniencia y bajo coste están logrando que el correo electrónico desplace al
correo ordinario para muchos usos habituales.
1
Índice [
mostrar]
Origen[
editar ·
editar fuente]
El correo electrónico antecede a
Internet, y de hecho, para que ésta pudiera ser creada, fue una herramienta crucial. En una demostración del
MIT (Massachusetts Institute of Technology) de 1961, se exhibió un sistema que permitía a varios usuarios ingresar a una IBM 7094 desde
terminales remotas, y así guardar archivos en el disco. Esto hizo posible nuevas formas de compartir información. El correo electrónico comenzó a utilizarse en 1965 en una supercomputadora de
tiempo compartido y para 1966 se había extendido rápidamente para utilizarse en las redes de computadoras.
En
1971,
Ray Tomlinson incorporó el uso de la
arroba (@) como divisor entre el usuario y la computadora en la que se aloja el correo, porque no existía la arroba en ningún nombre ni apellido. En inglés la arroba se lee «at» (en). Así, ejemplo@máquina.com se lee ejemplo en máquina punto com.
El nombre correo electrónico proviene de la analogía con el
correo postal: ambos sirven para enviar y recibir mensajes, y se utilizan "buzones" intermedios (
servidores), en donde los mensajes se guardan temporalmente antes de dirigirse a su destino, y antes de que el destinatario los revise.
Elementos[
editar ·
editar fuente]
Para que una persona pueda enviar un correo a otra, cada una ha de tener una dirección de correo electrónico. Esta dirección la tiene que dar un proveedor de correo, que son quienes ofrecen el servicio de envío y recepción. Es posible utilizar un programa específico de correo electrónico (cliente de correo electrónico o
MUA, del inglés Mail User Agent) o una interfaz web, a la que se ingresa con un
navegador web.
Dirección de correo[
editar ·
editar fuente]
Una dirección de correo electrónico es un conjunto de palabras que identifican a una persona que puede enviar y recibir correos. Cada dirección es única, pero no siempre pertenece a la misma persona, por dos motivos: puede darse un robo de cuenta e identidad y el correo se da de baja, por diferentes causas, y una segunda persona lo cree de nuevo.
Un ejemplo es persona@servicio.com, que se lee persona arroba servicio punto com. El signo @ (llamado
arroba) siempre está en cada dirección de correo, y la divide en dos partes: el nombre de usuario (a la izquierda de la arroba; en este caso, persona), y el
dominio en el que está (lo de la derecha de la arroba; en este caso, servicio.com). La arroba también se puede leer "en", ya que persona@servicio.com identifica al usuario persona que está en el
servidor servicio.com (indica una relación de pertenencia).
Una dirección de correo se reconoce fácilmente porque siempre tiene la @, donde la @ significa "pertenece a..."; en cambio, una
dirección de página web no. Por ejemplo, mientras que http://www.servicio.com/ puede ser una
página web en donde hay información (como en un libro),persona@servicio.com es la dirección de un correo: un buzón a donde se puede escribir.
Lo que hay a la derecha de la arroba es precisamente el nombre del proveedor que da el correo, y por tanto es algo que el usuario no puede cambiar, pero se puede optar por tener un dominio. Por otro lado, lo que hay a la izquierda depende normalmente de la elección del usuario, y es un identificador cualquiera, que puede tener letras, números, y algunos signos.
Es aconsejable elegir en lo posible una dirección fácil de memorizar para así facilitar la transmisión correcta de ésta a quien desee escribir un correo al propietario, puesto que es necesario transmitirla de forma exacta, letra por letra. Un solo error hará que no lleguen los mensajes al destino.
Es indiferente que las letras que integran la dirección estén escritas en mayúscula o minúscula. Por ejemplo, persona@servicio.com es igual a Persona@Servicio.Com.
Proveedor de correo[
editar ·
editar fuente]
Para poder enviar y recibir correo electrónico, generalmente hay que estar registrado en alguna empresa que ofrezca este servicio (gratuito o de pago). El registro permite tener una dirección de correo personal única y duradera, a la que se puede acceder mediante un nombre de usuario y una
Contraseña.
Hay varios tipos de proveedores de correo, que se diferencian sobre todo por la calidad del servicio que ofrecen. Básicamente, se pueden dividir en dos tipos: los correos gratuitos y los de pago.
Gratuitos[
editar ·
editar fuente]
Los correos gratuitos son los más usados, aunque incluyen algo de publicidad: unos incrustada en cada mensaje, y otros en la interfaz que se usa para leer el correo.
Muchos sólo permiten ver el correo desde un
sitio web propio del proveedor, para asegurarse de que los usuarios reciben la publicidad que se encuentra ahí. En cambio, otros permiten también usar un
programa de correo configurado para que se descargue el correo de forma automática.
Una desventaja de estos correos es que en cada dirección, la parte que hay a la derecha de la @ muestra el nombre del proveedor; por ejemplo, el usuario gapa puede acabar teniendo gapa@correo-gratuito.net. Este tipo de direcciones desagradan a algunos (sobre todo, a empresas
[1]) y por eso es común comprar o registrar gratuitamente (en ciertos países) un
dominio propio, para dar un aspecto más profesional.
De pago[
editar ·
editar fuente]
Los correos de pago normalmente ofrecen todos los servicios disponibles. Es el tipo de correo que un
proveedor de Internet da cuando se contrata la conexión.
También es muy común que una empresa
registradora de dominios venda, junto con el
dominio, varias cuentas de correo para usar junto con ese dominio (normalmente, más de 1).
Correo web[
editar ·
editar fuente]
Casi todos los proveedores de correo dan el servicio de
correo web: permiten enviar y recibir correos mediante un
sitio web diseñado para ello, y por tanto usando sólo un
navegador web. La alternativa es usar un programa de correo especializado.
El correo web es cómodo para mucha gente, porque permite ver y almacenar los mensajes desde cualquier sitio (en un servidor remoto, accesible por el sitio web) en vez de en un ordenador personal concreto.
Como desventaja, es difícil de ampliar con otras funcionalidades, porque el sitio ofrece un conjunto de servicios concretos y no podemos cambiarlos. Además, suele ser más lento que un programa de correo, ya que hay que estar continuamente conectado a sitios web y leer los correos de uno en uno.
Cliente de correo
También están los
clientes de correo electrónico, que son programas para gestionar los mensajes recibidos y poder escribir nuevos.
Suelen incorporar muchas más funcionalidades que el correo web, ya que todo el control del correo pasa a estar en el ordenador del usuario. Por ejemplo, algunos incorporan potentes filtros anti-
correo no deseado.
Por el contrario, necesitan que el proveedor de correo ofrezca este servicio, ya que no todos permiten usar un programa especializado (algunos sólo dan correo web). En caso de que sí lo permita, el proveedor tiene que explicar detalladamente cómo hay que configurar el programa de correo.
Esta información siempre está en su sitio web, ya que es imprescindible para poder hacer funcionar el programa, y es distinta en cada proveedor. Entre los datos necesarios están: tipo de conexión (
POP o
IMAP), dirección del servidor de correo, nombre de usuario y contraseña. Con estos datos, el programa ya es capaz de obtener y descargar nuestro correo.
El funcionamiento de un programa de correo es muy diferente al de un correo web, ya que un programa de correo descarga de golpe todos los mensajes que tenemos disponibles, y luego pueden ser leídos sin estar conectados a Internet (además, se quedan grabados en el ordenador). En cambio, en un sitio web se leen de uno en uno, y hay que estar conectado a la red todo el tiempo.
Algunos ejemplos de programas que realizan las funciones de cliente de correo electrónico son
Mozilla Thunderbird,
Outlook Express y
Eudora (ver
lista completa).
Funcionamiento
Escritura del mensaje
No se pueden mandar mensajes entre computadores personales o entre dos terminales de una computadora central. Los mensajes se archivan en un buzón (una manera rápida de mandar mensajes). Cuando una persona decide escribir un correo electrónico, su programa (o correo web) le pedirá como mínimo tres cosas:
Destinatario: una o varias direcciones de correo a las que ha de llegar el mensaje
Asunto: una descripción corta que verá la persona que lo reciba antes de abrir el correo
El propio mensaje. Puede ser sólo texto, o incluir formato, y no hay límite de tamaño
Además, se suele dar la opción de incluir
archivos adjuntos al mensaje. Esto permite traspasar datos informáticos de cualquier tipo mediante el correo electrónico.
Para especificar el destinatario del mensaje, se escribe su dirección de correo en el campo llamado Para dentro de la interfaz (ver imagen de arriba). Si el destino son varias personas, normalmente se puede usar una lista con todas las direcciones, separadas por comas o punto y coma.
Además del campo Para existen los campos CC y CCO, que son opcionales y sirven para hacer llegar copias del mensaje a otras personas:
Campo CC (
Copia de Carbón): quienes estén en esta lista recibirán también el mensaje, pero verán que no va dirigido a ellos, sino a quien esté puesto en el campo Para. Como el campo CC lo ven todos los que reciben el mensaje, tanto el destinatario principal como los del campo CCpueden ver la lista completa.
Campo CCO (
Copia de Carbón Oculta): una variante del CC, que hace que los destinatarios reciban el mensaje sin aparecer en ninguna lista. Por tanto, el campo CCO nunca lo ve ningún destinatario.
Un ejemplo: Ana escribe un correo electrónico a Beatriz (su profesora), para enviarle un trabajo. Sus compañeros de grupo, Carlos y David, quieren recibir una copia del mensaje como comprobante de que se ha enviado correctamente, así que les incluye en el campo CC. Por último, sabe que a su hermano Esteban también le gustaría ver este trabajo aunque no forma parte del grupo, así que le incluye en el campo CCO para que reciba una copia sin que los demás se enteren.
Entonces:
Beatriz recibe el mensaje dirigido a ella (sale en el campo Para), y ve que Carlos y David también lo han recibido
Carlos recibe un mensaje que no va dirigido a él, pero ve que aparece en el campo CC, y por eso lo recibe. En el campo Para sigue viendo a Beatriz
David, igual que Carlos, ya que estaban en la misma lista (CC)
Esteban recibe el correo de Ana, que está dirigido a Beatriz. Ve que Carlos y David también lo han recibido (ya que salen en el CC), pero no se puede ver a él mismo en ninguna lista, cosa que le extraña. Al final, supone que es que Ana le incluyó en el campo CCO.
Campo Reply-To (responder) Dirección dónde el emisor quiere que se le conteste. Muy útil si el emisor dispone de varias cuentas.
Campo Date (fecha, y hora, del mensaje) Fecha y hora de cuando se envío del mensaje. Si el sistema que envía el mensaje tiene la fecha y/u hora equivocadas, puede generar confusión.
Otros campos, menos importantes son:
Sender: Sistema o persona que lo envía
Received: Lista de los MTA que lo transportaron
Message-Id: Número único para referencia
In-Reply-to: Id. del mensaje que se contesta
References: Otros Id del mensaje
Keywords: Palabras claves de usuario
X-Usuario: Definibles por el usuario

Encabezado de un correo electrónico.
La cabecera del mensaje normalmente, se muestra resumida. Para ver todos los detalles bastará con expandir, mediante la opción oportuna, dicha cabecera.
Envío[
editar ·
editar fuente]
El envío de un mensaje de correo es un proceso largo y complejo. Éste es un esquema de un caso típico:
En este ejemplo ficticio, Ana (ana@a.org) envía un correo a Bea (bea@b.com). Cada persona está en un servidor distinto (una en a.org, otra en b.com), pero éstos se pondrán en contacto para transferir el mensaje.
Por pasos:
Ana escribe el correo en su programa
cliente de correo electrónico. Al darle a Enviar, el programa contacta con el
servidor de correo usado por Ana (en este caso, smtp.a.org). Se comunica usando un lenguaje conocido como protocolo
SMTP. Le transfiere el correo, y le da la orden de enviarlo.
El servidor SMTP ve que ha de entregar un correo a alguien del dominio b.com, pero no sabe con qué ordenador tiene que contactar. Por eso consulta a su
servidor DNS (usando el protocolo
DNS), y le pregunta quién es el encargado de gestionar el correo del dominio b.com. Técnicamente, le está preguntando el
registro MX asociado a ese dominio.
Como respuesta a esta petición, el servidor DNS contesta con el
nombre de dominio del servidor de correo de Bea. En este caso es mx.b.com; es un ordenador gestionado por el
proveedor de Internet de Bea.
El servidor SMTP (smtp.a.org) ya puede contactar con mx.b.com y transferirle el mensaje, que quedará guardado en este ordenador. Se usa otra vez el protocolo
SMTP.
Más adelante (quizás días después), Bea aprieta el botón "Recibir nuevo correo" en su programa
cliente de correo. Esto empieza una conexión, mediante el protocolo
POP3 o
IMAP, al ordenador que está guardando los correos nuevos que le han llegado. Este ordenador (pop3.b.com) es el mismo que el del paso anterior (mx.b.com), ya que se encarga tanto de recibir correos del exterior como de entregárselos a sus usuarios. En el esquema, Bea recibe el mensaje de Ana mediante el protocolo POP3.
Ésta es la secuencia básica, pero pueden darse varios casos especiales:
Si ambas personas están en la misma red (una
Intranet de una empresa, por ejemplo), entonces no se pasa por Internet. También es posible que el servidor de correo de Ana y el de Bea sean el mismo ordenador.
Ana podría tener instalado un servidor SMTP en su ordenador, de forma que el paso 1 se haría en su mismo ordenador. De la misma forma, Bea podría tener su servidor de correo en el propio ordenador.
Una persona puede no usar un
programa de correo electrónico, sino un
webmail. El proceso es casi el mismo, pero se usan conexiones
HTTP al webmail de cada usuario en vez de usar SMTP o IMAP/POP3.
Normalmente existe más de un servidor de correo (MX) disponible, para que aunque uno falle, se siga pudiendo recibir correo.
Si el usuario quiere puede almacenar los mensajes que envía, bien de forma automática (con la opción correspondiente), bien sólo para los mensajes que así lo desee. Estos mensajes quedan guardados en la carpeta "Enviados".
Recepción[
editar ·
editar fuente]
Cuando una persona recibe un mensaje de correo electrónico puede verse en la
bandeja de entrada un resumen de él:
Remitente (o De o De: o From o From: -en inglés-): esta casilla indica quién envía el mensaje. Puede aparecer el nombre de la persona o entidad que nos lo envía (o su apodo o lo que desee el remitente). Si quien envía el mensaje no ha configurado su programa o correo web al respecto aparecerá su dirección de correo electrónico.
Asunto: en este campo se ve el tema que trata el mensaje (o lo que el remitente de él desee). Si quien envía el mensaje ha dejado esta casilla en blanco se lee [ninguno] o [sin asunto]
Si el mensaje es una respuesta el asunto suele empezar por RE: o Re: (abreviatura de responder o reply -en inglés-, seguida de dos puntos). Aunque según de dónde proceda el mensaje pueden aparecer An: (del alemán antwort), Sv: (del sueco svar), etc.
Cuando el mensaje procede de un reenvío el asunto suele comenzar por RV: (abreviatura de reenviar) o Fwd: (del inglés forward), aunque a veces empieza por Rm: (abreviatura de remitir)
Fecha: esta casilla indica cuándo fue enviado el mensaje o cuándo ha llegado a la bandeja de entrada del receptor. Puede haber dos casillas que sustituyan a este campo, una para indicar la fecha y hora de expedición del mensaje y otra para expresar el momento de su recepción.
Además pueden aparecer otras casillas como:
Tamaño: indica el espacio que ocupa el mensaje y, en su caso, fichero(s) adjunto(s)
Destinatarios (o Para o Para: o To o To: -en inglés-): muestra a quiénes se envió el mensaje
Datos adjuntos: si aparece una marca (habitualmente un clip) significa que el mensaje viene con uno o varios ficheros anexos
Prioridad: expresa la importancia o urgencia del mensaje según el remitente (alta -se suele indicar con un signo de exclamación-, normal -no suele llevar marca alguna- o baja -suele indicarse con una flecha apuntando para abajo-)
Marca (de seguimiento): si está activada (p.e. mostrando una bandera) indica que hay que tener en cuenta este mensaje (previamente lo ha marcado la persona que lo ha recibido)
Inspeccionar u omitir: pinchando en esta casilla se puede marcar el mensaje para inspeccionarlo (suelen aparecer unas gafas en la casilla y ponerse de color llamativo -normalmente rojo- las letras de los demás campos). Pinchando otra vez se puede marcar para omitirlo (suele aparecer el símbolo de "prohibido el paso" en este campo y ponerse en un tono suave -normalmente gris- las letras de las demás casillas). Pinchando una vez más volvemos a dejar el mensaje sin ninguna de las dos marcas mencionadas
Cuenta: Si utilizamos un
cliente de correo electrónico configurado con varias cuentas de correo esta casilla indica a cuál de ellas ha llegado el mensaje en cuestión
Primeras palabras del (cuerpo del) mensaje
Los mensajes recibidos pero sin haber sido leídos aún suelen mostrar su resumen en negrita. Después de su lectura figuran con letra normal. A veces si seleccionamos estos mensajes sin abrirlos podemos ver abajo una previsualización de su contenido.
Si el destinatario desea leer el mensaje tiene que abrirlo (normalmente haciendo (doble) clic sobre el contenido de su asunto con el puntero del ratón). Entonces el receptor puede ver un encabezado arriba seguido por el cuerpo del mensaje. En la cabecera del mensaje aparecen varias o todas las casillas arriba mencionadas (salvo las primeras palabras del cuerpo del mensaje). Los ficheros adjuntos, si existen, pueden aparecer en el encabezado o debajo del cuerpo del mensaje.
Una vez que el destinatario ha recibido (y, normalmente, leído) el mensaje puede hacer varias cosas con él. Normalmente los sistemas de correo (tanto
programas como
correo web) ofrecen opciones como:
Responder: escribir un mensaje a la persona que ha mandado el correo (que es sólo una). Existe la variante Responder a todos, que pone como destinatarios tanto al que lo envía como a quienes estaban en el campo CC
Reenviar (o remitir): pasar este correo a una tercera persona, que verá quién era el origen y destinatario original, junto con el cuerpo del mensaje. Opcionalmente se le puede añadir más texto al mensaje o borrar los encabezados e incluso el cuerpo (o parte de él) de anteriores envíos del mensaje.
Marcar como spam: separar el correo y esconderlo para que no moleste, de paso instruyendo al programa para que intente detectar mejor mensajes parecidos a éste. Se usa para evitar la publicidad no solicitada (
spam)
Archivar: guardar el mensaje en el ordenador, pero sin borrarlo, de forma que se pueda consultar más adelante. Esta opción no está en forma explícita, ya que estos programas guardan los mensajes automáticamente.
Borrar: Se envía el mensaje a una carpeta Elementos eliminados que puede ser vaciada posteriormente.
Mover a carpeta o Añadir etiquetas: algunos sistemas permiten catalogar los mensajes en distintos apartados según el tema del que traten. Otros permiten añadir marcas definidas por el usuario (ej: "trabajo", "casa", etc.).
Problemas[
editar ·
editar fuente]
Artículos principales:
Spam y
Antispam.
El principal problema actual es el
correo no deseado, que se refiere a la recepción de correos no solicitados, normalmente de
publicidad engañosa, y en grandes cantidades, promoviendo
pornografía y otros productos y servicios de calidad sospechosa.
2 3 4
Usualmente los mensajes indican como remitente del correo una dirección falsa. Por esta razón, es más difícil localizar a los verdaderos remitentes, y no sirve de nada contestar a los mensajes de correo no deseado: las respuestas serán recibidas por usuarios que nada tienen que ver con ellos. Por ahora, el servicio de correo electrónico no puede identificar los mensajes de forma que se pueda discriminar la verdadera dirección de correo electrónico del remitente, de una falsa. Esta situación que puede resultar chocante en un primer momento, es semejante por ejemplo a la que ocurre con el correo postal ordinario: nada impide poner en una carta o postal una dirección de remitente aleatoria: el correo llegará en cualquier caso. No obstante, hay tecnologías desarrolladas en esta dirección: por ejemplo el remitente puede firmar sus mensajes mediante
criptografía de clave pública.
Además del correo no deseado, existen otros problemas que afectan a la seguridad y veracidad de este medio de comunicación:
los
virus informáticos, que se propagan mediante ficheros adjuntos infectando el ordenador de quien los abre
la
suplantación de identidad, que es correo fraudulento que generalmente intenta conseguir información bancaria
los
bulos (bromas, burlas, o hoax), que difunden noticias falsas masivamente
las
cadenas de correo electrónico, que consisten en reenviar un mensaje a mucha gente; aunque parece inofensivo, la publicación de listas de direcciones de correo contribuye a la propagación a gran escala del 'correo no deseado y de mensajes con virus, suplantadores de identidady engaños.
Servicios de correo electrónico[
editar ·
editar fuente]
Principales proveedores de servicios de correo electrónico gratuito:
Gmail:
webmail,
POP3 e
IMAP
Outlook.com:
webmail y
POP3
Yahoo! Mail:
webmail y
POP3 con publicidad
Los servicios de correo de pago los suelen dar las
compañías de acceso a Internet o los
registradores de dominios.
También hay servicios especiales, como
Mailinator, que ofrece cuentas de correo temporales (caducan en poco tiempo) pero que no necesitan registro.
 Mostrar todo
Mostrar todo que representa el archivo de sonido. Para reproducir el sonido mientras ofrece la presentación, puede configurarlo de forma que se inicie automáticamentecuando se muestre la diapositiva, iniciarlo con un clic de mouse (ratón), iniciarlo automáticamente con un retardo oreproducirlo como parte de una secuencia de animación. También puede reproducir música desde un CD oagregar una narración a la presentación.
que representa el archivo de sonido. Para reproducir el sonido mientras ofrece la presentación, puede configurarlo de forma que se inicie automáticamentecuando se muestre la diapositiva, iniciarlo con un clic de mouse (ratón), iniciarlo automáticamente con un retardo oreproducirlo como parte de una secuencia de animación. También puede reproducir música desde un CD oagregar una narración a la presentación.




























